STR 재연 및 분석
업데이트:
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis을 재연하고 결과를 정리한 글입니다.
Setting Parameters
module
- Transformation: None / TPS
- FeatureExtraction: VGG / RCNN / ResNet
- SequenceModeling: None / BiLSTM
- Prediction: CTC / Attn
data
- train_data = data_lmdb_release/training
- valid_data = data_lmdb_release/validation
- batch_size = 192
- select_data = [‘MJ’, ‘ST’]
- batch_ratio = [‘0.5’, ‘0.5’]
- total_data_usage_ratio = 1.0
- batch_max_length = 25 : maximum label length
- data_filtering_off = False
image
- imgH = 32
- imgW = 100
- rgb = False
characters
- character = 0123456789abcdefghijklmnopqrstuvwxyz : character label
- sensitive = False : 대소문자 구분 유무
training
- num_iter = 300000 : training iteration (epoch이라고 보면 될 듯)
- valInterval = 2000 : validate interval, 몇번마다 validate할지 (validation마다 best accuracy와 norm ED를 찾아 saved_model에 저장한다.)
- saved_model = .pth
- FT = False
- adam = False : default인 Adadelta가 아닌 adam을 사용할지
- lr = 1 : learning rate [Adadelta default]
- beta1 = 0.9
- rho = 0.95 : decay rate rho [Adadelta default]
- eps = 1e-08 :
-
grad_clip = 5 : gradient clipping value
- PAD = False
framework
Transformation : TPS
- num_fiducial = 20 : fiducial point 개수
Feuture Extrator
- input_channel = 1
- output_channel = 512
Sequence Modeling : LSTM
- hidden_size = 256 : hidden state size
Prediction (CTC/Attn)
- num_class = 37 / 38 : character label set [CTC = 37, Attn = 38]
etc
- manualSeed = 1111 : random seed setting
- workers = 4 : data loading workers 수
- num_gpu = 1
Experiment Result
다음은 해당 논문의 appendix D를 정리한 글입니다.
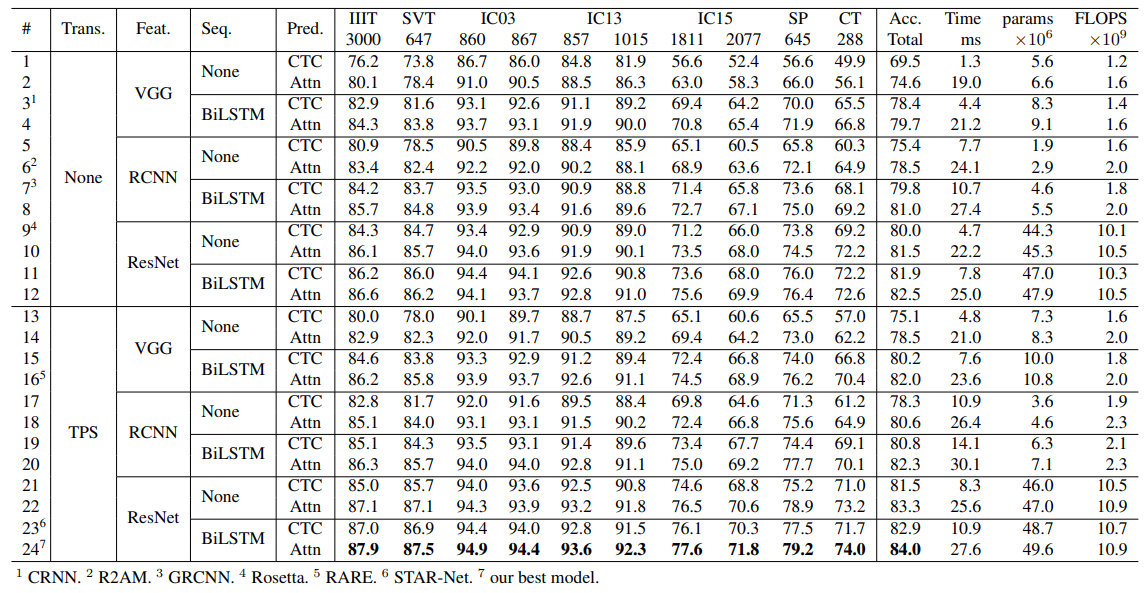
- Tranformation stage : None -> TPS (+1~5%)
- Feature Extrator stage : VGG -> RCNN -> ResNet
- Sequence modeling stage : None -> BiLSTM (+1~2%)
- Prediction stage : CTC -> Attn (+2~5%)
1. Transformation Stage
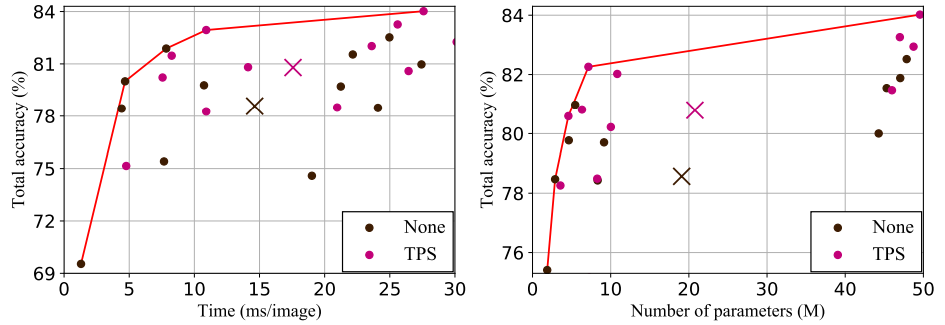
2. Feature Extration Stage
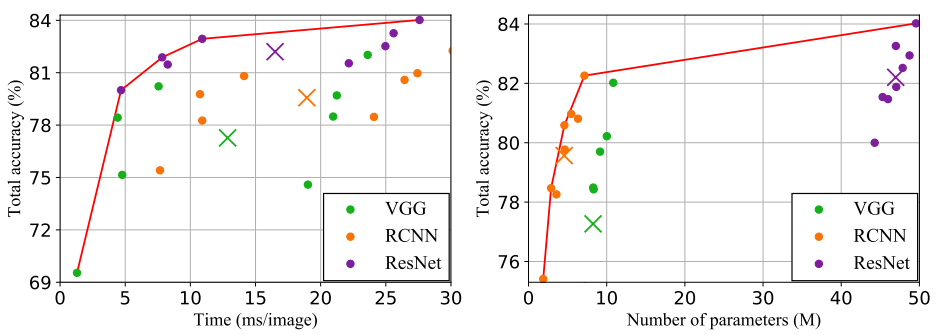
VGG가 가장 시간이 적게 걸리지만 낮은 정확도를 보인다. RCNN은 가장 시간이 걸리지만 가장 적은 메모리와 VGG보다 높은 정확도를 보인다. ResNet이 가장 높은 정확도를 가지지만, 다른 module에 비해 많은 메모리를 필요로 한다. 따라서, 메모리 제약이 존재하면 RCNN이 가장 좋은 trade-off이고, 그렇지 않다면 ResNet을 사용해야 한다. 시간적인 측면에서 세 module 모두 차이가 크지 않으므로 극단적인 경우에만 고려한다.
3. Sequence Modeling Stage
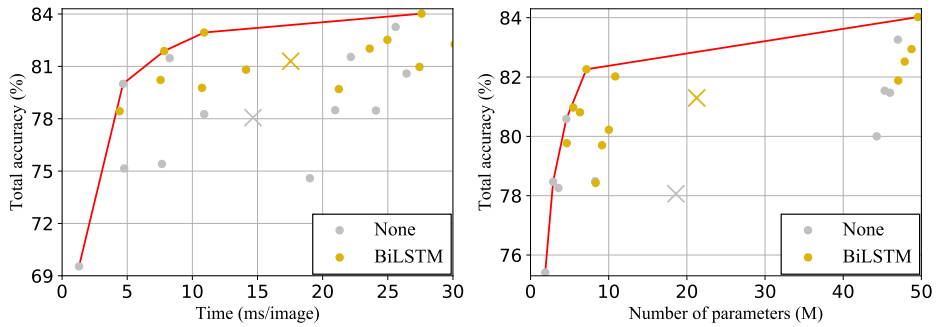
TPS와 비슷하지만, BiLSTM을 사용하면 비슷한 시간과 메모리에 비해 더 높은 정확도로 향상시킨다.
4. Prediction Stage
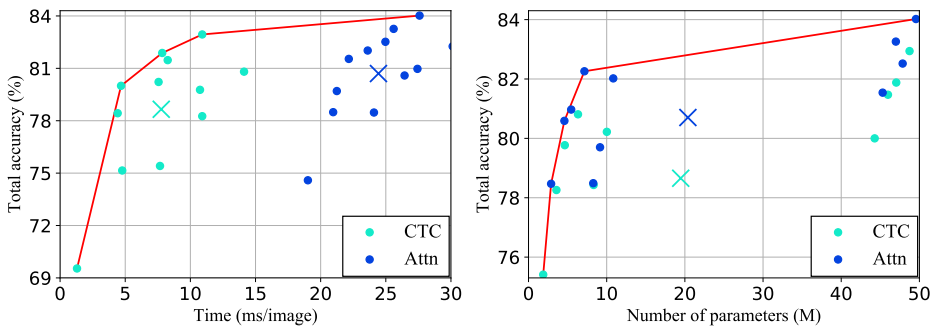
Attn은 CTC에 비해 정확도를 높이려고 할 때 시간이 오래 걸린다.
재연 및 분석
-
먼저 여러 combination에 대해 재연하였고, 30만번 반복하는 작업이 매우 오랜 시간을 필요로 한다는 것을 확인했다. 몇몇은 직접 train하였고, 몇몇은 이미 학습한 파일을 통해 train하였다. 논문에서 공개한 정확도와 거의 일치하였고, 한번은 20만번 반복하여 학습하였는데 30만번에 해당하는 정확도와 비슷하였다.
-
네가지 stage에 대해 조사하였다. https://hryang06.github.io/str/STR-module/
-
특히 prediction stage에 해당하는 attention에 대해 알아보았다. https://hryang06.github.io/str/Attn/
-
위의 정확도를 확인하면 ctc보다는 attn이 더 정확도를 높여준다는 사실을 확인할 수 있다. 하지만 여전히 ctc와 attn 모두 사용하고 있다. 둘의 차이를 알아보기 위해 이미 학습된 코드를 몇몇 이미지로 테스트 해보았다.
-
각 dataset마다 10개 이미지(gray scale)와 함께 label과 prediction을 확인하였다.
-
각 dataset의 결과를 csv파일로 저장하여 FALSE인 경우에 대해 확인하였다.
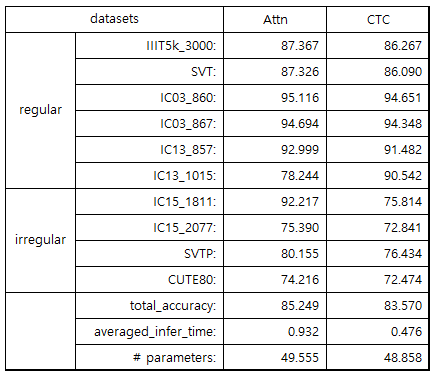
IC13 (1015) : regular dataset
| CTC | Attn |
|---|---|
| 90.542 | 92.217 |
- attn만 맞춘 경우 (34)
- ctc만 맞춘 경우 (17)
- 둘 다 틀린 경우 (62)
ctc
- feature map으로 부분으로 예측을 하다 보니 문제가 생긴다고 생각함
- attention은 한 문자로 보고 예측을 하지만, ctc는 일부를 보고 부분부분 예측하다 보니 문자가 끊겨 있는 경우 예측이 힘든 것 같음
- 반대로 부분부분 예측하다 보니 잘린 문자에 대해서는 제대로 인식하는 경우도 있음
- forever : 어두워서 잘 보이지 않음 / attn은 fonever로 예측했지만, ctc는 정확하게 예측함
- SECOM : M의 앞부분이 잘려있음 / attn은 secow로 예측했지만, ctc는 정확하게 예측함
attn
- attention을 전혀 잘못한 경우
- attention은 잘하였으나 글자를 제대로 인식하지 못한 경우
both
- wordbox가 제대로 되어 있지 않는 경우 –> recognition보다는 detection의 문제로 보아야 한다고 생각함
-
글자가 길어질수록 정확성 떨어짐
- 꺾인 거에 대해 제대로 인식을 하지 못함
- 1의 윗부분이 꺾여 있음에도 불구하고 i나 l로 읽는 경우 많음
- t로 잘못 읽는 경우도 있음
- 두꺼운 글자 ex) d
- 애매하게 잘린 부분에 대해 인식하고 예측하는 경우 존재함(gt에는 포함되지 않음)
- 한 문자를 여러 문자로 예측하는 경우
- SNOUT의 N을 I와 V로 인식함
문자가 끊겨 있는 경우
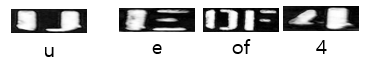
u는 attn과 ctc 모두 ij로 예측하여 틀렸다. attn의 경우, attention을 잘못 한 것으로 예측된다. ctc의 경우, 잘려진 문자에 대해 모두 맞추지 못했는데, 이는 feature map을 대상으로 예측하기 때문에 부분 부분 인식한 것으로 보인다. (순서대로 ie, ijf, 4j로 예측함)
IC15 (1922) : irregular dataset
| CTC | Attn |
|---|---|
| 72.841 | 75.390 |
- attn만 맞춘 경우 (124)
- ctc만 맞춘 경우 (75)
- 둘 다 틀린 경우 (398)
ctc
- 역시나 feature map으로 부분으로 예측을 하다 보니 문제가 생긴다고 생각함
- FairPrice : P를 F로 예측함 (ctc 특성상 왼쪽의 특징부터 확인하면 P와 F를 헷갈릴 수 있음)
- 한글자를 빼먹는 경우가 많음
- citibank -> ctbanck : i를 빼먹음, i처럼 얇은 문자의 경우 종종 빼먹음
attn
- attention을 잘못하는 경우 -> 문자가 잘 보이지만, 제대로 예측할 수 없음

- I와 T를 반대로 예측한 경우
both
- 애매하게 잘린 부분에 대해 인식하고 예측하는 경우 존재함(gt에는 포함되지 않음)
- ground truth가 잘못 적힌 이미지
- vehicles -> veichles(gt) , oiletries -> oiletreies(gt) , chabuton -> chanbuton(gt)
- 한 문자를 여러 문자로 예측하는 경우 -> 그나마 attention이 강력함
- DARUE의 U를 L과 I로 인식함
- 특정 문자 구분을 잘 못함
- O와 Q와 a와 0
- H와 N
rotate image
- rotate한 이미지가 많다.
- 일반적으로 attn, ctc 모두 예측하지 못한다. (attention도 못하는 것으로 보임)
- 현재 str은 수평으로 이루어진 이미지(왼쪽에서 오른쪽으로)만을 예측할 수 있다.
- rotate 이미지를 예측하려면, transformation에서 rotate를 하여 network에서 학습할 수 있도록 해야 한다.
- 예측한 결과(대부분 i)를 보면 rotate를 하지 못한 것 같다. (이미지 보이는 대로 예측한 것으로 보임)