Attention-based sequence prediction 이해하기
업데이트:
Attention-based sequence prediction에 관한 글입니다.
[참고 논문]
- [RARE] Robust Scene Text Recognition with Automatic Rectification (1603)
- [FAN] Focusing attention: Towards accurate text recognition in natural images (1709)
- [AON] AON: Towards Arbitrarily-Oriented Text Recognition (1711)
- [EP] Edit Probability for Scene Text Recognition (1805)
Attention based decoder
attention based decoder가 실질적인 Prediction stage에서 Attention(Attn)을 의미한다. decoder는 \(y_t\)를 예측한다.
\[each\ step\ t, y_t = softmax(W_{_0S_t} + b_0)\]- \(W_0, b_0\) : trainable parameters
- decoder LSTM hidden state at time t
- \(c_t\) : context vector = glimpse vector([FAN] AN은 glimpse vector를 생성시키고 FN은 reasonable한지 판단함)

- \(\alpha_t\) : attention weight = alignment factors : center vector(AN), input image의 attention region과 대응됨
attention based decoder는 아래 셋 모두 비슷하다.
-
FAN : ResNet(extrator) + BiLSTM(256 hidden state) + attention based decoder(AN[LSTM + softmax] + FN)
-
AON : BCNN(extrator) + AON + FG + attention based decoder(BiLSTM + attention + softmax)
-
EP : 7-Conv-vased / ResNet(extrator) + EP-based attention decoder(기존의 attention based decoder 뒤에 확률 분포에 대해 다시 한번 예측하는 듯)
RARE
TPS-VGG-BiLSTM-Attn
SRN : Sequence Recognition Network
- attention-based model로, input image로부터 sequence를 인식한다.
- input : rectified image(STN output), 이상적으로 문자들이 왼쪽에서 오른쪽으로 수평적 이미지
- input으로부터 sequential representation을 extract하고, 단어를 인식한다.
- SRN은 encoder와 decoder를 가진다.
- encoder : input image로부터 sequential representation을 extract한다.
- decoder : sequential representation에 따른 sequence를 생성한다.
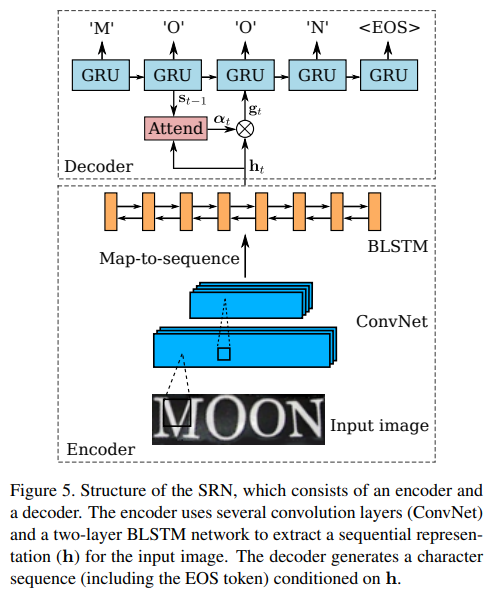
1. Encoder : Convolutional-Recurrent Network
CNN으로부터 feature map을 추출하여, map-to-sequence 연산을 통해 feature map을 여러 연속된 조각으로 분리한다.
[Figure 5]
- several convolutional layers : (input image의 robust하고 high-level의 descriptions이 포함된) feature maps 생성한다.
- feature maps : depth D * height H * width W
- map-to-sequence operation : map의 columns를 왼쪽에서 오른쪽으로 가져와 vectors로 flatten한다.
- sequence of W vectors : DW dimensions
- column : local image region(receptive field)에 대응하고, 해당 region에 대한 descriptor이다.
- BLSTM : 2 layer Bidirectional Long-Short Term Memory network
- receptive field 크기에 의해 제한되므로, feature sequence는 limited image contexts에 영향을 준다.?
- sequence 내의 long-term dependencies를 model하기 위해서 사용한다.
- 양방향으로 sequence 내의 dependencies를 분석할 수 있는 recurrent network
- output은 input과 동일한 길이(L = W)의 sequence
2. Decoder : Recurrent Character Generator
FAN : Focusing Attention Network
?-ResNet-?-Attn
기존 attention-based method 문제
- complicated, low-quality 이미지에서 성능이 떨어짐
- cannot get accurate alignments between feature areas and targets for such images –> “attention drift”
논문에서 구현한 scene text recognition
- ResNet 기반 CNN을 이용해 deeper representation을 extract한다. (아마 이 논문이 처음)
- alignment factors와 glimpse vectors를 생성하기 위해 sequence of features를 AN으로 보낸다.
- 이때, FN을 이용해 glimpse vectors가 reasonable한지 판단하고, AN이 보다 reasonable한 glimpse vectors를 생성할 수 있도록 feedback을 제공한다. 이를 통해, AN은 처리된 이미지에서 target characters의 올바른 영역에 적절하게 attention할 수 있다.
FAN method
FAN = AN + FN
Figure2 (a)를 보면 attention이 제대로 이루어지지 않고 있다. 이러한 문제를 “attention drift”라고 한다. (b)와 같이 FN을 추가하여 문제점을 해결한다.
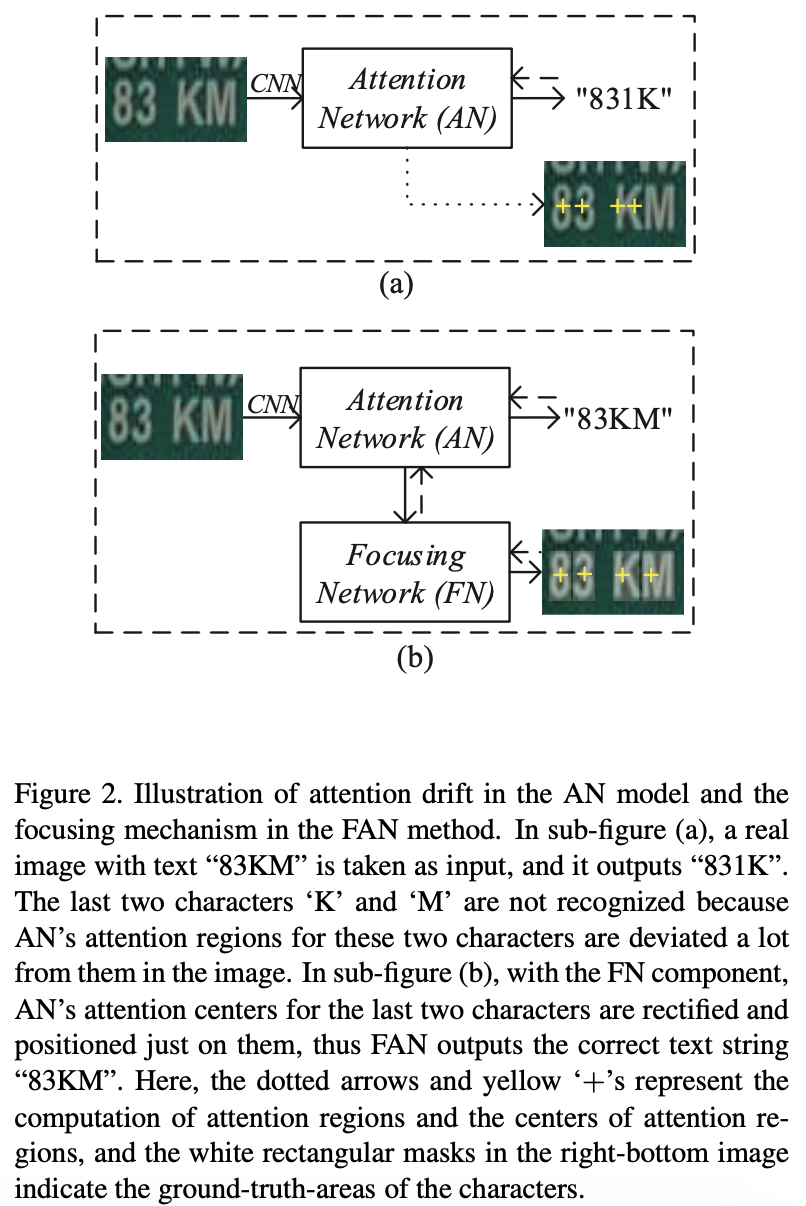
- alignment factors(target labels & features 사이) 생성된다. 각 alighment factor는 input image의 attention region과 대응한다.
- bad alignment(벗어나거나 unfocused attention region)는 poor recognition을 보인다.
- FN component는…
- 1) 각 target label에 대해 attention region 위치를 찾고,
- 2) 대응하는 glimpse vector와 함께 attention region으로부터 dense prediction을 한다.
- 이렇게 FN은 glimpse vector가 reasonable한지 판단할 수 있다.

summary
- FN은 AN에서 제공하는 glimpse vector를 바탕으로, input image의 attention region에 대해 dense output을 생성한다.
- AN은 FN의 feedback을 바탕으로, glimpse vector를 업데이트한다.
AN : Attention Network
recognizing character targets (기존 방법처럼)
1. attention based decoder
- RNN, inut image I로부터 target sequence를 직접 생성한다.
- 실제로, image \(I\)는 CNN-LSTM에 의해 a sequence of feature vectors로 종종 encode된다. \(I = Encoder(h_1, ... , h_T)\)

- \(g_t\) : glimpse vector
- Generate() : feed-forward network
-
RNN() : LSTM recurrent network
- EOS(end-of-sentence) token을 target set에 추가한다.
- decoder는 가변적인 길이의 sequence를 다루기 때문에 EOS가 나오면 문자 생성을 완료한다.
2. Loss Function
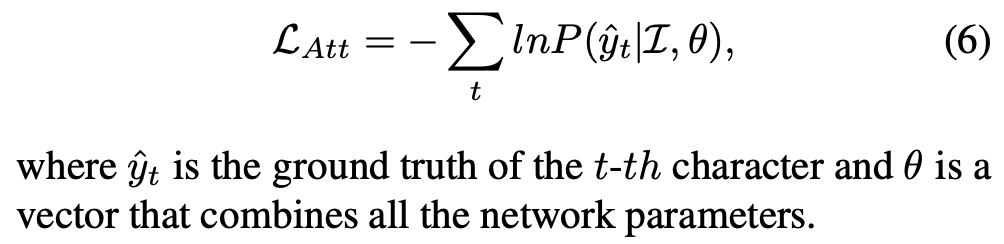
3. drawbacks
1) attention drift
- complicated, low-quality 이미지에 영향을 많이 받는다.
- 정확하지 않은 alignment factors를 생성한다.
- integration of glimpse vectors에 대한 alignment constraint(제약)이 모델에 없기 때문이다.
- 이로 인해, attention regions과 ground-truth regions가 불일치 할 수 있다.
- FAN 논문에서는 이를 해결하는 것을 목표로 한다.
- [FN]을 도입하여, 각 target character로 AN의 attention을 제한하고자 한다.
2) huge scene text data(e.g. 8000만 개 synthetic data)에 대해서는 모델을 train하기 어렵다.
FN : Focusing Network
adjusting attention by evaluating whether AN pays attention properly on the target areas in the images
- attention model에서, 각 feature vector는 input image의 영역과 mapping 된다.
- 이는 convolution strategy를 바탕으로 target character를 localize하는데 사용될 수 있다.
- BUT! 계산된 targets의 attention regions 일반적으로 정확하지 않다. 특히, complicated & low-quality 이미지에서.
- 이러한 attention drift 문제를 바로잡기 위해 FN을 소개한다.
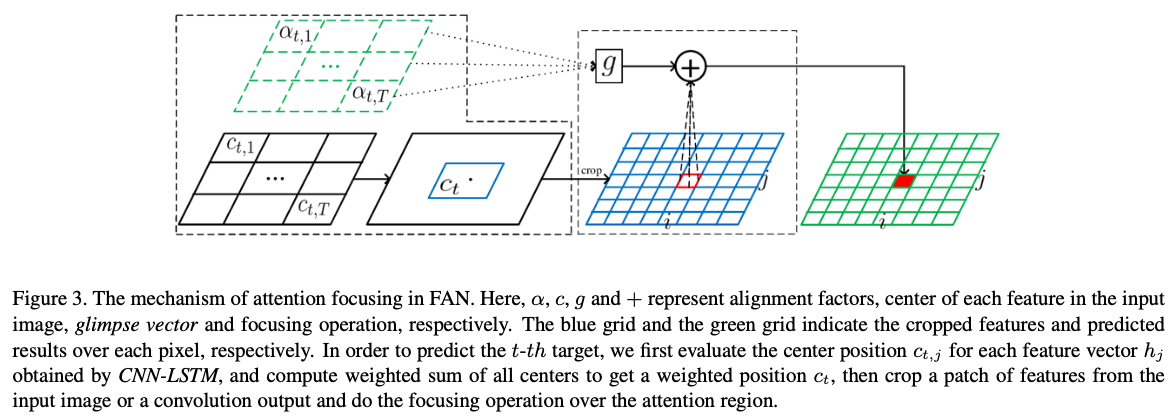
1. computing attention center
: computing the attention center of each predicted label
convolution/pooling operation
- input : \(N * D_i * H_i * W_i\)
- output : \(N * D_o * H_o * W_o\)
(N : batch size, D : number of channels, H/W : height/width of feature maps)
layer L의 (x,y)에 대해, (7)과 같이 bounding box coordinates r로 layer L-1의 receptive field을 계산한다.
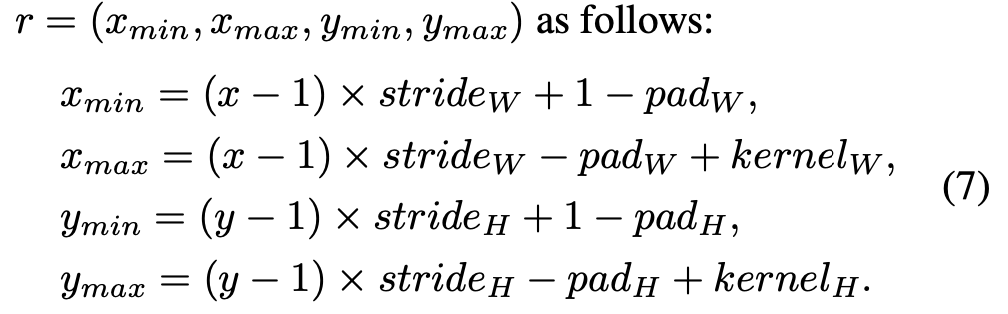
t번째 step에서 (7)을 반복적으로 계산함으로써 input image에서의 \(h_j\)의 receptive field을 계산하고, attention center인 recetive field의 center를 선택한다.
\[c_{t,j} = location(j) \quad (8)\]- location() : receptive field의 center를 계산하는 함수.
input image의 target \(y_t\)의 attention center는 (9)와 같이 계산한다.
\[c_t = \sum_{j=1}^T \alpha_{t,j} c_{t,j} \quad (9)\]2. focusing attention on target regions
: focusing attention on target regions by generating the probability distributions on the attention regions
위에서 계산한 target \(y_t\)의 attention center를 이용하여, input image 또는 convolution layer output에서 사이즈가 \(P(P_H, P_W)\)인 feature maps의 patch를 자른다.
\[F_t = Crop(F, c_t, P_H, P_W) \quad (10)\]- \(F\) : image 또는 convolution feature maps
- \(P\) : input image에서 ground-truth regions의 최대 크기
cropped feature maps를 이용하여, attention region에 대한 energy distribution을 계산한다.
\[e_t^{(i,j)} = tanh(R_{g_t} + S F_t^{(i,j)} + b) \quad (11)\]- \(R, S\) : trainable parameters
- \((i,j)\) : \((i * P_W + j)\)번째 feature vector를 가리킨다.
- glimpse vector와 attention region의 \((i,j)\)번째 feature 값의 energy 크기를 나타낸다.
선택한 region(잘라낸 patch)에 대한 probability distribution(확률 분포)은 다음과 같이 계산한다.
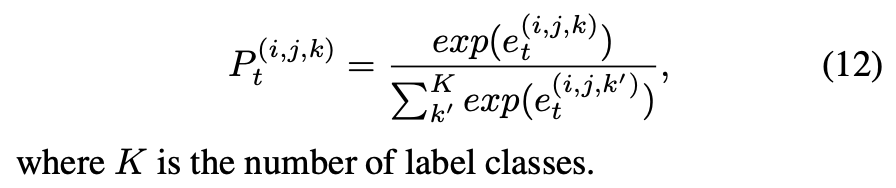
- \(K\) : label class 개수
focussing loss function
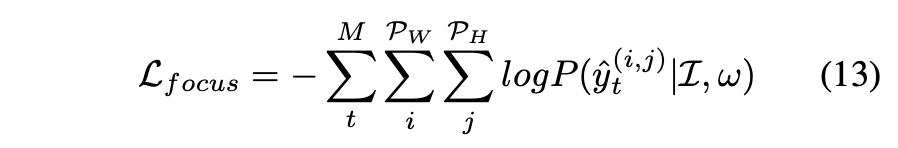
- \(y_t^{(i,j)}\) : ground-truth pixel label
- \(w\) : 모든 FN parameters를 결합한 vector
- loss는 character annotations를 가진 image의 subset에 대해서만 추가된다.(character label gt가 존재하는 경우에만 사용한다.)
FN은 오직 train에서 사용되고, inference(추론)에서는 사용되지 않는다.
FAN training
ResNet + (BiLSTM) + AN + FN = FAN 이렇게 하나의 네트워크로 만든다.(Figure4 참고)
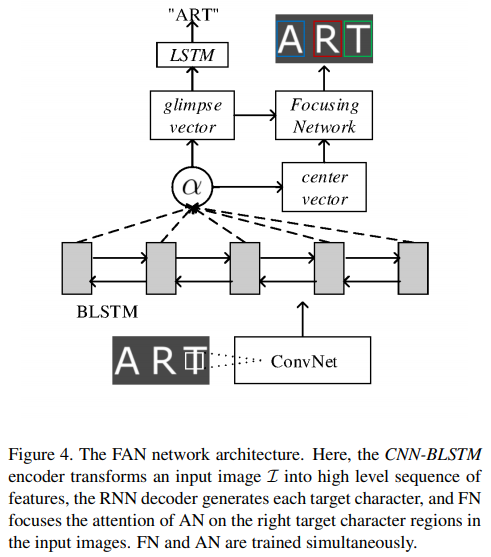
- CNN-BiLSTM encoder : input image \(I\)를 high level sequece of feautures로 변환한다.
- RNN(LSTM) decoder : 각 target character를 생성한다.
- AN : extrated features를 이용하여, alignment factors(center vector)와 glimpse vectors를 생성한다.
- FN : input image의 적절한 target character 영역에 AN의 attention을 집중시킨다.
- FN과 AN은 동시에 train한다.
전체 loss function(objective function)은 target-generation과 attention-focusing 둘다 고려하여 구성된다.
\(L = (1 - \lambda)L_{Att} + \lambda L_{focus}\)
- \(\lambda (0 <= \lambda < 1)\) : tunable parameters, AN과 FN loss의 weight를 결정한다.
standard back-propagation에 의해 train된다.
decoding
- attention-based decoder : 함축적으로 학습한 character-label 확률 통계로부터 characters의 output sequence를 생성하는 것을 말한다.
- 제한이 없는 text recognition 과정에서(lexicon-free), 쉽게 가장 가능성있는 character를 선택한다.
- 반면 제한된 text recognition에서는(크기가 다른 어휘), 모든 어휘(lexicon words)에 대해 조건부 확률 분포를 계산하고, 가장 높은 확률의 것을 output 결과로 선택한다.
AON : Arbitrary Oriented Network
contributions
- 4방향으로 scene text features와 문자 배치 단서를 추출하기 위해 AON(Arbitrary Oriented Network) 제안한다.
- 학습된 배치 단서와 함께 4방향 features를 융합하기 위해 FG(Filter Gate)를 설계한다. FG는 integrated feature sequence 생성을 담당한다.
- AON, FG, 그리고 attention-based decoder를 character recognition framework에 통합한다. 전체 network는 character-level bounding box 없이 직접 end-to-end 학습할 수 있다.
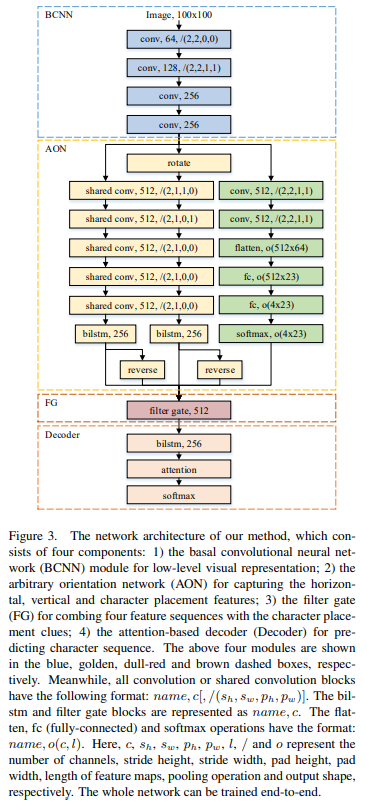
1. BCNN : Basal Convolutional Neural Network
extract low-level visual features
- text image의 기본적인 시각적 표현을 capture한다.
- output : group of feature maps(반드시 square feature maps이어야 함)
- 계산 비용과 graphic memory를 줄일 수 있다.
- 기본 feature extrator로 4 convolutional block을 사용한다.
2. Multi-Direction Feature Extraction Module
AON : Arbitrary Oriented Network
capturing arbitrarily-oriented text features and the corresponding character placement clues
수평, 수직, 배치 특징을 추출하기 위해 각각 HN, VN, CN을 필요로 한다.
-
HN : Horizontal Network
-
VN : Vertical Network
-
CN : Character placement clue Network
FG : Filter Gate
integrating multi-direction features by using the character placement clues.
3. attention based decoder
input feature sequence \((\hat h_1, ... , \hat h_L)\) 로부터 target sequence \((y_1, ... , y_M)\) 를 직접 생성하는 RNN이다. decoder는 가변적인 길이의 seqeuence 생성을 할 수 있다. 특별한 end-of-sequence(EOS) token을 추가하여, EOS가 등장하면 decoder는 문자 생성을 완료한다.
t번째 step에서
\(y_t = softmax(W^T s_t) \quad (1)\)
- \(W_T\) : learnable parameter
- \(s_t\) : RNN hidden state
\(s_t = RNN(y_{t-1}, g_t, s_{t-1}) \quad (2)\)
- \(RNN()\) : LSTM recurrent network

- \(g_t\) : glimpse vector([FAN] AN은 glimpse vector를 생성시키고 FN은 reasonable한지 판단함)
- \(\alpha_t\) : attention weight = alignment factors : input image의 attention region과 대응됨
Network training
Character Sequence Decoding
EP : Edit Probability
기존 방식의 문제점
- 기존 방법은 모델을 최적화하기 위해 frame-wise maximal liklihood loss를 사용한다.
- training 하면, ground truth strings와 attention’s output sequences of probability distribution 사이 misalignment는 혼란스럽게 하며 training을 잘못 유도할 수 있다.
- 결과적으로 training 비용이 많이 들며 인식 정확도를 떨어뜨린다.
문제 해결
- STR에 대한 Edit Probability(EP)라는 새로운 방법을 제안한다.
- EP는 누락되거나 불필요한 문자 발생 가능성을 고려하면서, input image에서 조건화된 확률 분포의 output sequence에서 문자열을 생성할 확률을 효율적으로 estimate하고자 한다.
- 장점) training 과정은 누락되거나 불필요하거나 인식되지 못한 문자에 집중할 수 있으며, misalignment 문제의 영향을 완화하거나 극복할 수 있다.
- 결과적으로, EP는 STR 성능을 실질적으로 향상시킬 수 있다.
STR
- traditional methods with handcrafted features
- 개별적인 character detection & recognition을 위한 handcrafted visual features를 추출한다.
- heuristic rules/language model을 기반으로 이 문자를 단어로 intergrate한다.
- ex) training SVM(Support Vector Machine), training character classifier with extracted HOG descriptors
- handcrafted features의 낮은 표현 능력 때문에 만족스러운 인식 성능을 보일 수 없었다.
- Naive deep neural-network-based methods
- robust visual features를 추출하기 위해 개발되었다.
- ex1) character features를 추출하기 위해 5 hidden layers의 FC를 채택하고 문자를 인식하기 위해 n-gram language model을 적용함
- ex2) character feature representation을 위해 CNN based framework 개발하고, character generations를 위해 heuristic rules를 적용함
- 전/후처리(segmentation of each character / non-maximum suppression)에 의해 character sequence를 인식하는데, 복잡한 배경과 연속 문자 사이의 부적절한 거리 때문에 어려움이 있다.
- sequence-based methods
- 최근 researchers는 text recognition을 sequence learning 문제로 보았다.
- text image -> sequence of features로 deep neural network을 이용하여 encoding한다.
- sequence recognition techniques를 이용하여 character sequence를 직접 생성한다.
- ex) CNN이나 RNN을 이용하여 visual feature representation을 캡쳐하는 end-to-end neural network를 제안하였고, 예측과 타겟 sequence 사이 조건부 확률을 계산하기 위해 neural network output과 CTC loss를 결합함
- attention-based methods
- text image를 feature representations로 encoding하기 위해 CNN과 RNN을 결합하고, 모델을 최적화하기 위해 frame-wise loss를 사용한다.
- training 과정에서, ground truth sequence와 output probability distribution 사이에서 misalignment은 training 알고리즘과 결과를 잘못 유도하여 성능이 낮아질 수 있다.
misalignment problem
- 음성 인식에서도 발생! -> multi-task learning framework 내에서 joint CTC-attnetion model을 이용하여 문제를 해결하고자 하였다.
- joint CTC-attention model은 STR(문자 인식)에서는 효과적이지 않다.
- 기본 방법과는 달리, 새로운 방법 EP를 제안하였다.
- gt text와 output 확률 분포(pd) 사이 misalignment를 누락되거나 불필요한 문자 발생 결과로 처리하여, input image에 조건화된 string의 확률을 추정함
- EP는 misalignment problem을 효과적으로 처리할 수 있다.
EP method
정확한 STR을 위해 attention-based models을 효과적으로 train하는 것이 목표이다.
모든 가능한 edit paths의 확률을 더하여 평가한다.
EP-based Attention Decoder
기존의 attention decoder는 다음과 같다. FAN과 AON과 비슷하다.
j번째 단계에서,

- \(\omega, W, V, b, v\) : trainable parameters
EP calculation은 다음과 같다.

Edit Probability
attention-based encoder/decoder
- CNN-based feature extrator(7-conv-based / ResNet-based)을 이용하여 visual feature representation을 얻음
- attention model을 사용하여 확률 분포의 output sequence를 생성함