STR - What is Wrong with Scene Text Recognition Model Comparisons? Dataset and Model Analysis
업데이트:
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis 논문 정리입니다.
Abstraction
현재 STR(Scene Text Recognition)에 대한 모델이 많이 등장하였지만, 전체적으로 공정하게 비교하기 쉽지 않다. -> 일치하는 training과 evaluation dataset을 선택하지 않기 때문이다.
이 논문에서는 다음과 같은 3가지에 대해 기여를 하였다.
- training dataset과 evaluation dataset의 불일치성과 이로 인한 performance gap에 대하여 조사한다.
- 통합된 four-stage STR framework를 소개한다. 이전에 제안된 STR module의 광범위한 평가할 수 있고, 새로운 조합의 module을 발견할 수 있다.
- 성능(정확성, 속도, 메모리, 하나로 일관된 training & evaluation dataset)에 대한 모듈별 기여도를 분석한다.
1. Introduction
발전한 OCR(Optical Character Recognition, 광학 문자 인식)은 깨끗한 문서에 대하여 성공적인 성능을 보여주었지만, 이전의 OCR은 그렇지 못하였다. STR은 현실 세계에서 발생하는 다양한 형태의 텍스트와 캡쳐되는 장면의 불완전한 조건으로 인해 어렵다.
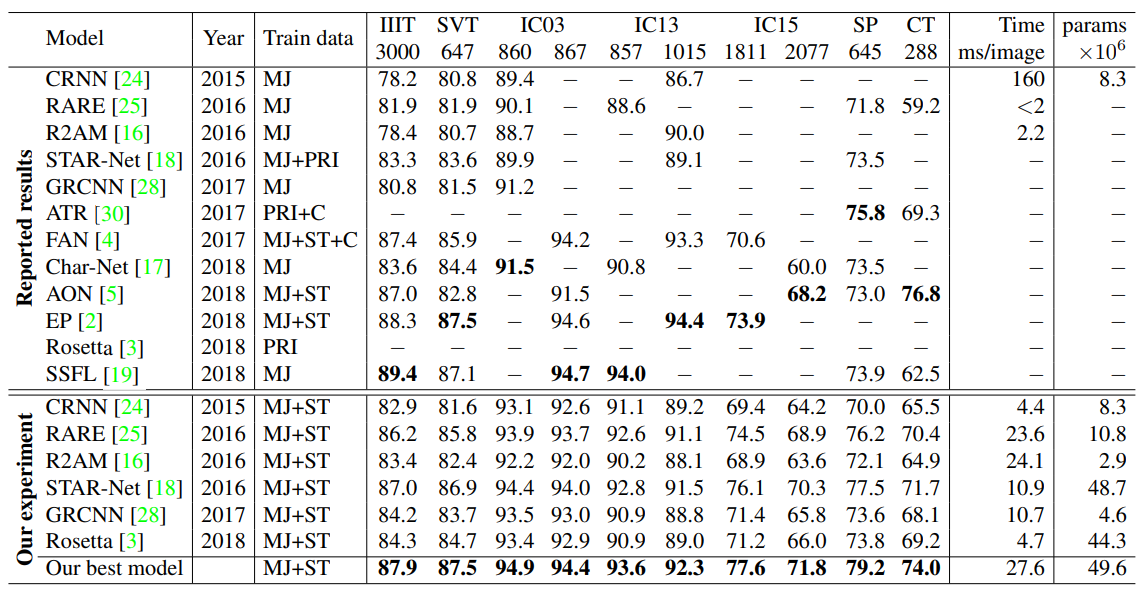
이러한 문제를 다루기 위해 여러가지 model 등장하였다. 하지만 1) training datasets 2) evaluation datasets
로 인해 서로 비교하기가 어려웠다. 같은 IC13을 사용하더라도 서로 다른 subset을 사용하는 경우, 성능 차이가 15% 넘게 발생한다.
이 논문에서는 다음과 같은 이슈에 대해 다룬다.
- STR 논문에 자주 사용되는 모든 training과 evaluation datasets를 분석한다.
- 통합하는 STR framework를 소개한다.
- module 별 기여도를 분석한다. (accuracy, speed, memory demand, under a unified experimental setting)
추가적으로 실패사례 또한 분석한다.
2. Dataset Matters in STR
| dataset | examples |
|---|---|
| Training Dataset | MJ, ST |
| Evaluation Dataset | IIIT, SVT, IC03, IC13, IC15, SP, CT |
2.1. Synthetic datasets for training
대부분의 STR model은 synthetic datasets를 training datasets로 사용하였다.

| dataset | images |
|---|---|
| MJSynth (MJ) | 8.9M word box images |
| SynthText (ST) | 5.5M word box images |
이전에는 MJ와 ST의 다양한 조합을 사용하였는데 이는 불일치성이 발생하도록 한다. 제안된 module로 인해 성능이 향상된건지 더 크고 나은 training data를 사용해서 향상된건지 알 수가 없다. 따라서, 앞으로의 STR research에서는 같은 training set을 사용하는 것이 비교에 도움이 된다.
2.2. Real-world datasets for evaluation
7개의 real-world STR datasets가 학습된 STR model에 대하여 evaluation을 위해 사용된다. 몇몇은 다른 subset을 사용하는데 이로인해 비교의 불일치가 발생하게 된다.
텍스트의 난이도와 기하학적 레이아웃에 따라 regular와 irregular dataset으로 나눈다.

1) Regular Datasets
regular dataset은 수평으로 배치된 텍스트로, 간격이 있는 텍스트도 포함하고 있다. STR에서 쉬운 data에 속한다.
| dataset | for training | for evaluation | content | collect |
|---|---|---|---|---|
| IIIT5K-Words (IIIT) | 2000 images | 3000 images | 텍스트 이미지로 반환되는 검색어 | Google image searchs |
| Street View Text (SVT) | 256 images | 647 images | noisy, blurry, 저해상도 | Google Street View |
| ICDAR2003 (IC03) | 1156 images | 1110 images (867, 860) |
- | ICDAR 2003 Robust Reading competition |
| ICDAR2013 (IC13) | 848 images | 1095 images (1015, 857) |
- | ICDAR 2013 Robust Reading competition |
- IC03 : evaluation datasets로 사용하는 subset이 867 images와 860 images 두 개가 존재한다. 867 images는 3 문자보다 작거나 영숫자가 아닌 문자를 포함하는 경우를 제외한 set이고, 860 images는 867에서 7개의 word box를 제외한 set이다.
- IC13 : evaluation datasets로 사용하는 subset이 1015 images와 857 images 두 개가 존재한다. 1015 images는 영숫자가 아닌 문자를 포함하는 경우를 제외한 set이고, 857 images는 1015 images에서 3 문자보다 작은 경우를 뺀 set이다.
2) Irregular Datasets
irregular dataset은 더 어려운 케이스를 포함하고 있다. 구부러지고 회전되거나 왜곡된 텍스트가 일반적이다.
| dataset | for training | for evaluation | content | collect |
|---|---|---|---|---|
| ICDAR2015 (IC15) | 4468 images | 2077 images (1811, 2077) |
noisy, blurry, rotated, 저해상도 | ICDAR 2015 Robust Reading competition, Google Glasses |
| SVT Perspective (SP) | - | 645 images | perpective projections | Google Street View |
| CUTE80 (CT) | - | 288 cropped images | curved text images | natural scenes |
- IC15 : evaluation datasets로 사용하는 subset이 1811 images와 2077 images 두 개가 존재한다. 이전의 논문에서는 1811 images만 사용했다. 1811 images는 영숫자가 아닌 문자를 포함하는 경우를 빼고, 심하게 회전되거나 원근감이 있거나 구부러진 경우 또한 제외하였다.
이전의 model은 서로 다른 기준의 dataset을 가지고 평가했다. IC03의 경우에는 data 7개로 인해 0.8%의 큰 성능차를 보인다.
3. STR Framework Analysis
 CRNN(Convolutional-Recurrent Neural Network) : 첫번째 CNN과 RNN의 STR을 위한 combination
CRNN(Convolutional-Recurrent Neural Network) : 첫번째 CNN과 RNN의 STR을 위한 combination
= CNN(Convolutional Neural Networks) + RNN(Recurrent Neural Networks)

3.1. Transformation Stage (Tran.)
input text image를 normalize한다.
-
None
-
TPS(Thin-Plate Spline) : STN(Spatial Transformer Network)의 변형, smooth spline interpolation 사용
3.2. Feature Extraction Stage (Feat.)
input image를 문자 인식 관련 속성에 초점을 둔 표현과 연결하고 관련없는 특징(font, color, size, background)은 억제한다.
다음은 모두 CNN의 변형으로, STR의 feature extrators로 쓰인다.
-
VGG : convolution layer 여러개 + fully connected layer 조금
-
RCNN : 문자 모양에 따른 receptive field 조정을 위해 재귀적으로 적용 가능
-
ResNet : 더 deep한 CNN의 training을 쉽게 하는 residual connections
3.3. Sequence Modeling Stage (Seq.)
다음 stage를 위해 문맥 정보를 캡쳐한다. (독립적으로 하는 것보다 강력해짐)
-
None : 계산 복잡도와 메모리 소비 때문에 사용하지 않는 경우도 있음
-
BiLSTM
3.4. Prediction Stage (Pred.)
-
CTC(Connectionist Temporal Classification) : 고정된 개수의 feature가 주어지더라도 고정되지 않은 수의 sequence를 예측할 수 있음 -> 각 H의 열에 있는 문자를 예측하고 반복되는 문자와 공백을 삭제하여 full character sequence를 고정되지 않은 문자 스트림으로 수정함
-
Attn(Attention-based sequence prediction) : output sequence를 예측하기 위해 input sequence 내의 information flow를 캡쳐함
4. Experiment and Analysis
모든 가능한 STR module combinations(232*2 = 24)를 four-stage framework로부터 평가하고 분석하였다.
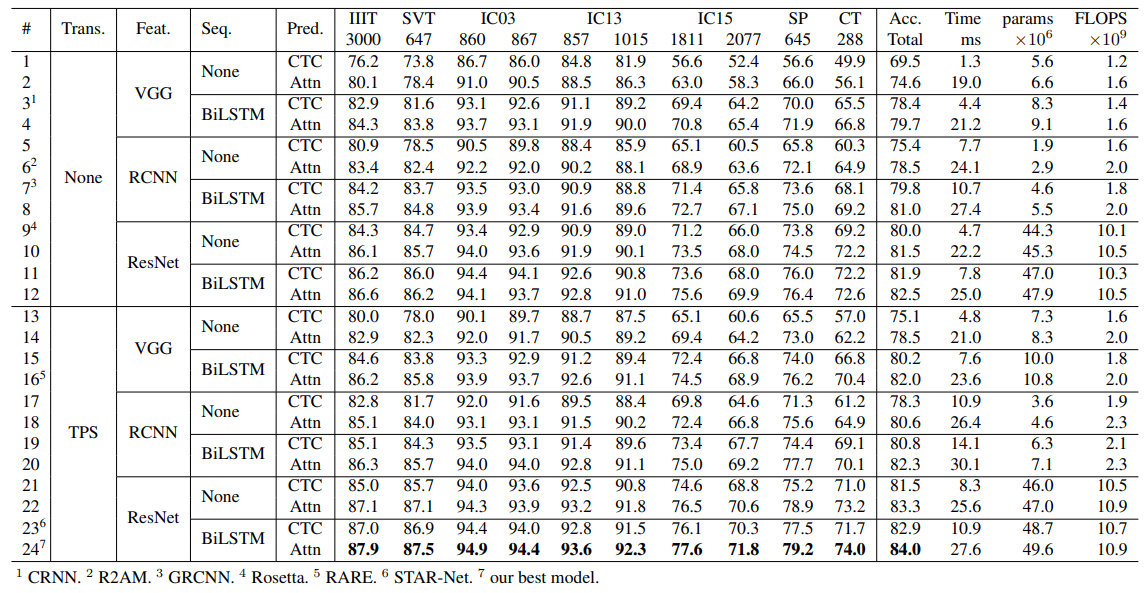
4.1. Implement Detail
- training batch size : 192
- num of iteration : 300K
- decay rate : 0.95 (AdaDelta optimizer)
- gradient clapping value : 5
- 모든 parameter는 He’s method의 초기화를 따른다.
-
training data : MJSynth 8.9M + SynthText 5.5M (14.4M)
- validation data : IC13 IC15 IIIT SVT
- IC03 train data 사용X : IC13와 겹친다 (34 scene images = 215 word boxes)
- 2000 training steps마다 validate한다. (set에서 가장 높은 정확도를 가지는 model을 택함)
- evaluation data : IIIT 3000 + SVT 647 + IC03 867 + IC13 1015 + IC15 2077 + SP 645 + CT 288 (8539 images)
- only alphabets & digits
- 5trials(매번 random seeds를 다르게 초기화)를 통해 accuracy의 평균 구함
- same environment for fair speed comparison!
4.2. Analysis on Training Datasets
MJSynth와 SynthText를 각각 사용하는 것보다 둘의 combination으로 train하였을 때, 더 높은 accuracy를 보인다는 것을 확인하였다. (자신들의 best model로 실험한 결과, 약 4.1% 더 높았다)
MJSynth 20% (1.8M) + SynthText 20% (1.1M)의 조합(2.9M으로 SynthText의 반 크기)으로 하였을 때 각각 사용한 것보다 더 좋은 accuracy를 보였다. 다시말해, training images의 개수보다는 training data의 다양성이 더 중요하다는 것을 알 수 있다.
4.3. Analysis on Trade-offs for Module Combinations
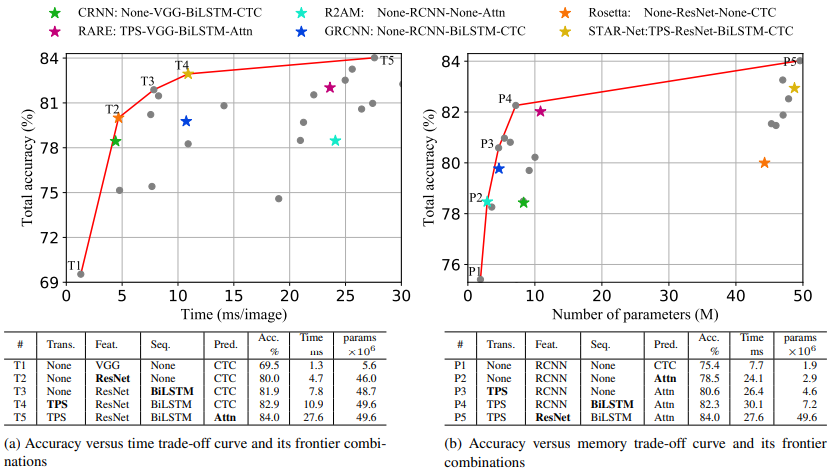
- accuracy-time trade-offs
: T1 ~ T5까지 ResNet, BiLSTM, TPS, Attn 순서대로 추가- ResNet, BiLSTM, TPS : 속도가 늦어지는 반면 정확도가 빠르게 높아짐(+13.4%)
- Attn : 속도가 많이 늦어진 만큼 정확도가 높아지지 않음(+1.1%)
- accuracy-memory trade-offs
: P1 ~ P5까지 Attn, TPS, BiLSTM, ResNet 순서대로 추가- Attn, TPS, BiLSTM : 메모리 사용을 크게 하지 않음 -> 가벼우면서도 정확성 높여줌
- ResNet : 메모리를 많이 사용하지만(7.2M -> 49.6M) 그 만큼 정확도가 높아지지 않음(+1.7%)
- accuracy-speed는 prediction(CTC/Attn), accuracy-memory는 feature extrator(ResNet)에서 영향을 크게 미치므로 필요에 따라 선택해야 한다.
4.4. Module Analysis
-
accuracy-time ResNet, BiLSTM, TPS, Attn 순서대로 upgrade하였을 때 가장 효율적이었다. (T1 -> T5)
-
accuracy-memory RCNN, Attn, TPS, BiLSTM, ResNet 순서대로 upgrade하였을 때 가장 효율적이었다. (P1 -> P5)
서로 반대 순서로 upgrade하였을 때 효율적이지만, 결과적으로 가장 효율적이 combination(TPS-ResNet-BiLSTM-Attn)은 동일하다.

-
TPS transformation : curved and perspective texts를 normalize하여 standardized view로 변환함
-
ResNet feaure extrator : 표현력 향상 (심한 배경 혼란, 처음 보는 font의 경우 개선됨)
-
BiLSTM sequence modeling : 관련없는데 잘라진 문자를 무시함
-
Attn prediction : 사라지거나 누락된 문자를 찾음
4.5. Failure Case Anlysis

- Calligraphic Fonts : 브랜드 font, 가게 이름
- 정규화하는 feature extrator 사용하자!
- font가 overfitting될 수 있으므로 regularization 하자!
-
Vertical Texts : 현재 대부분 horizontal text image 제공
- Special Characters : 현재 이러한 case train안함 -> alphanumeric characters로 취급하여 fail
- 그냥 sepcial character train하자! (IIIT에서 87.9% -> 90.3%로 정확도 오름)
-
Heavy Occlusions : 현재 문맥정보를 광범위하게 사용하지 않음
- Low Resolution : 현재 다루지 않음
- image pyramids
- super-resolution modules
- Label Noise : incorrect labels 찾음
- mislabeling (special characters 포함x) 1.3%
- mislabeling (special characters 포함) 6.1%
- mislabeling (case-sensitive) 24.1%
5. Conclusion
이 논문은 일관되지 않은 실험 설정 때문에 문제가 있던 STR model의 기여도를 분석하였다. 주요 STR method 중 공통 framework와 일관된 dataset(7 banchmark evaluation dataset + 2 training dataset)을 소개하여, 공정한 비교를 제공하였다.