Bert is Not All You Need for Commonsense Inference 논문 정리
업데이트:
Bert is Not All You Need for Commonsense Inference 논문 정리입니다.
abstract
본 논문은 input sentences에 기술된 것 이상의 지식을 요구하는 commonsense inference, 특히 natural language inference(NLI)와 casual inference(CI)의 과제를 연구한다. state-of-the-art는 commansenses knowledge으로서 knowledge나 contextual embeddings를 가진 neural model이었다. (ex.BERT)
우리의 연구 질문은 다음과 같다.
- Is BERT all we need for NLI and CI?
- If not, what is missing information and where to find such information?
많은 연구에서 BERT가 캡처하는 것을 연구해 왔지만, BERT의 한계는 다소 학습이 부족하다. 우리의 기여는 commansense inference에서 BERT의 한계를 관찰한 다음, missing information을 포함하는 complementary resources를 활용하는 것이다. 구체적으로, BERT와 complementary resource를 두 가지 heterogeneous modalities로 모델링하고, multimodal intergration approaches의 장단점을 탐구한다. 또한 제안된 intergration models이 NLI와 CI 모두에서 state-of-the-art를 달성한다는 것을 증명한다.
1. Introduction
Inference는 대화에서 주어진 모델이 단순히 language understanding을 가장하기 위해 pattern을 matching 하는 것인지, understanding에서 정말로 유능한 것인지 시험하는 중요한 과제이다. 대표적인 과제가 NLI(자연어 추론)과 CI(인과 추론)이다. 둘 다 주어진 premise p에 대해 hypothesis h가 사실인지를 판단하는 것으로 볼 수 있다.
NLI 모델의 목표는 p에 대해 h를 entailment, contradiction, neutral 세 가지 inferential relationships로 분류하는 것이다.
예를 들어,
- \(p\) : It was still night.
- \(h\) : The sun is shining.
- \(commansense~ knowledge\) : The sun cannot shine in the night.
correct inference가 contradiction이기 위해서는 위와 같은 commansense knowledge(상식)를 필요로 한다.
input에 \(p^\prime\)과 같은 required premise가 있는 것들이 누락되어(missing) 있기 때문에, commansence inference 정의한다. 다른 예로sms p,h 쌍을 casual/not casual로 분류하는 task인 CI가 있다. 위의 예는 그러한 task에 대한 effective model이 \(p^\prime\)을 알고 예측에 사용하기 위해 필요하다는 동기를 부여한다.
related works
기존 \(p^\prime\)의 출처
- uncarated text corpora
- night, sun entities는 textual co-occurences에서 관찰될 수 있다.
- curated Knowledge Graph(KG)
- KG triple \((h,r,t)\)는 head/tail entities (h = sun, t = night)와 그 relation \(r\) (“does not shine”)을 curate한다.
contributions
-
our key contribution : outperforming CE(Contextual Embedding), by intergrating with complementary sources - SE(Structure Embedding) and DE(Description Embedding)
-
two research questions
- What is the missing information in BERT?
- Can we find such information from curated sources to augment BERT?
- missing information에 대해서, BERT의 knowledge는 co-occurrences에 bias된다고 가정한다.
- 예) sum - night의 negative association이 캡처되지 않을 수 있다. 오히려 이 문제와 상관없는 strong association이 캡처될 수 있다.
- 한편, KG의 human-curated relations는 두 relationships를 명확히 구분한다.
- curated & uncurated sources 모두 사용하는 모델이 NLI/CI tasks 둘다 더 효과적이라는 것을 보여줌으로써 이러한 가정을 검증한다.
- 이러한 관찰은 [8]과 일관됨 : KG와 BERT의 complementary nature를 주장하지만, 두가지 양상을 “fuse(융합)”하는 방법은 논의하지 않는다.
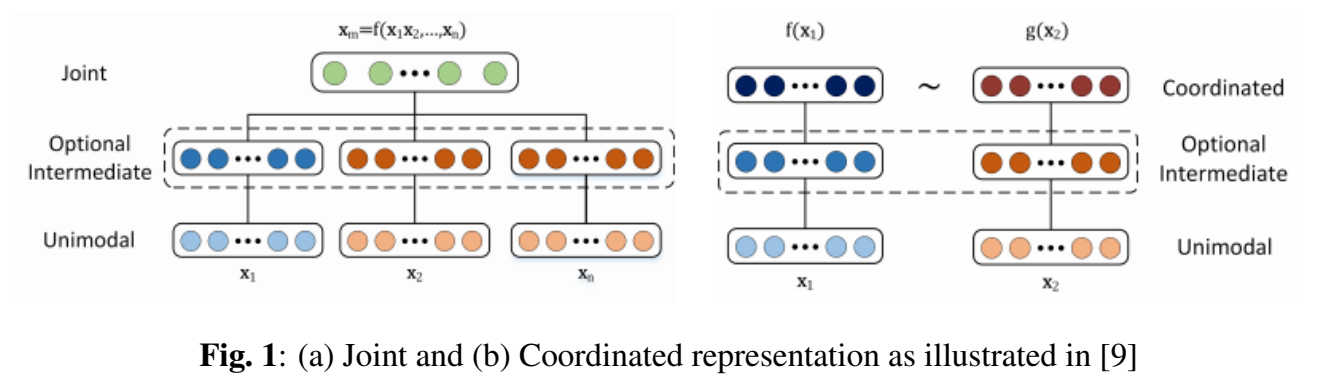
- KG와 BERT의 intergration을 multimodality fusion problem으로 제기하고, 기존 fusion models를 두 주요 categories로 분류한 survey[9]를 참고한다.
- (1) Joint representation : unimodal signals를 same shared representations space로 combine한다.
- (2) Coordinated representation : unimodal signals를 따로따로 처리하지만, “paired” cross-modal alignment training에 의해 유도되는 coordination constraints를 enforce한다.
- 예)
contribution : to propose a BERT finetuning
key distinction : do not require to retrain BERT, nor annotate additional cross-modal alighments
2. Preliminaries and Related Work
2.1. KG Embedding : SE and DE
2.2. Corpus : CE
2.3. Relation of our work
OWE (Open World Extension)
An open-world extension to knowledge graph completion models
3. Proposed Approach
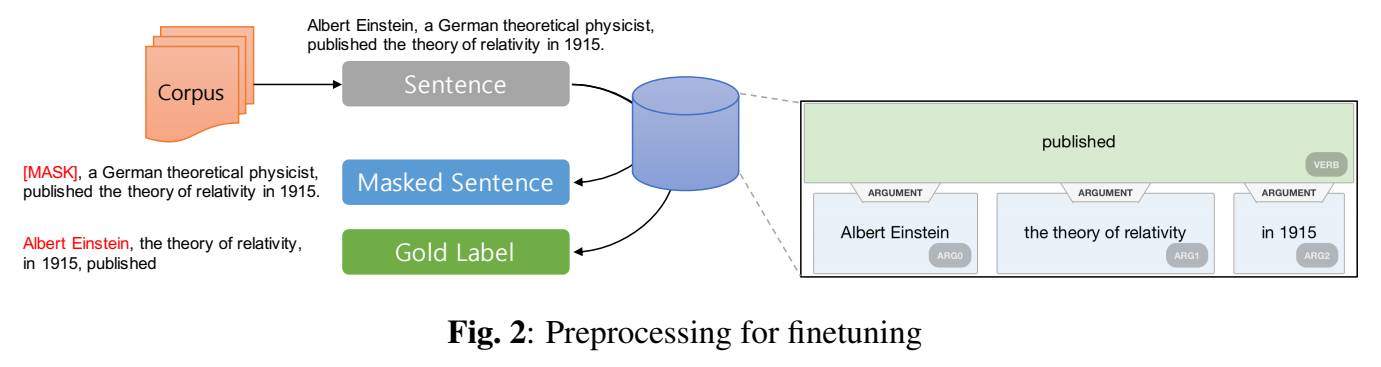
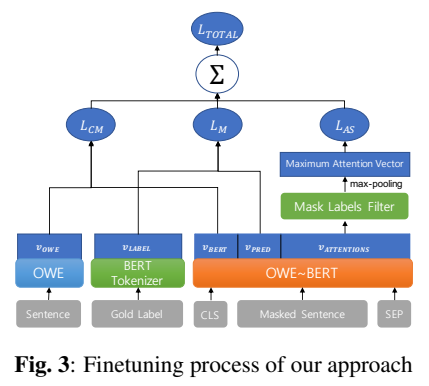
3.1. Joint : OWE+BERT
3.2. Coordinated : OWE ~ BERT
4. Results
4.1. Pre-trained Models
BERT base pretrained model (bert-base-uncased)
4.2. Datasets
- MultiNLI
- Stree Test : Antonym matched/mismatched
- COPA (Choice of Plausible Alternatives)
4.3. Results
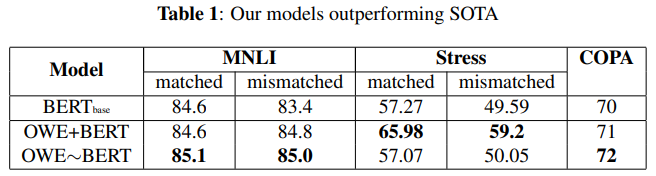
5. Conclusion
NLI와 CI를 위한 BERT와 knowledge graph와 같은 uncurated & curated sources의 knowledge를 융합하는 문제를 연구하였다. 두 가지 source 모두 commansense inference를 보완한다는 것을 관찰하였다. 이 문제를 modality intergration으로 제시하였고, NLI와 CI에서 SOTA를 능가하는 multimodal approach를 제안하였다.