Transformer 이해하기 - Attention is All You Need
업데이트:
Attention Is All You Need 논문 관련 정리한 글입니다.
Transformer
RNN(recurrent model)은 순차적인 특성이 유지되는 장점이 있지만, long-term dependency(정보 간의 거리가 멀어지면 서로 이용하지 못함)에 취약하다. Transformer는 RNN을 사용하지 않고 Attention mechanism만을 사용하여 input과 output의 dependency를 포착한다.
RNN은 t번째 hidden state를 얻기 위해서 t-1번째 hidden state가 필요하다. 순서대로 계산될 필요가 있어 병렬처리를 할 수 없으며 계산 속도가 느리다. Transformer는 학습 시 encoder에서는 각 position(단어)에 대해 attention을 해주고, decoder에서는 masking 기법을 이용해 병렬 처리가 가능하다.
model
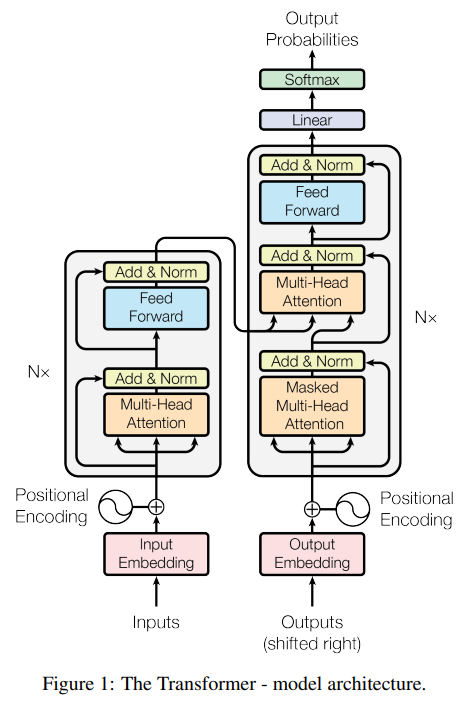
Encoder & Decoder Stacks
Encoder
- N개의 동일한 layer ( \(N = 6\) )
- 각 layer는 두개의 sub-layers를 가짐
- multi-head self-attention mechanism
- (simple, position-wise fully connected) feed-forward network
- 두 sub-layer에 residual connection(input을 output으로 그대로 전달)을 사용한 후, layer normalization을 한다.
- 이때, sub-layer의 output dimension = embedding dimension ( \(d_{model} = 512\) )
Decoder
- N개의 동일한 layer ( \(N = 6\) )
- 각 layer는 두개의 sub-layers를 가짐
- multi-head self-attention mechanism
- (simple, position-wise fully connected) feed-forward network
- 두 sub-layer에 residual connection(input을 output으로 그대로 전달)을 사용한 후, layer normalization을 한다.
- 이때, sub-layer의 output dimension = embedding dimension ( \(d_{model} = 512\) )
Attention
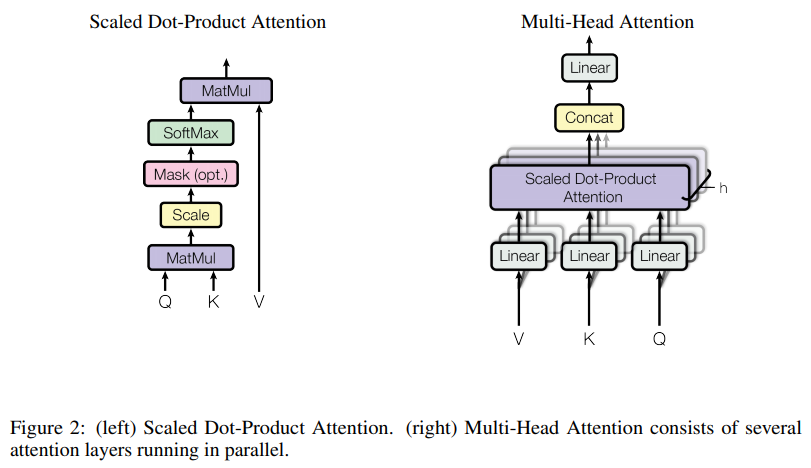
Position-wise Feed-Forward Networks
Embeddings & Softmax
Positional Encoding
참고
https://www.theteams.kr/teams/2829/post/69500
https://namhandong.tistory.com/48
https://medium.com/@omicro03/attention-is-all-you-need-transformer-paper-%EC%A0%95%EB%A6%AC-83066192d9ab
https://blog.naver.com/PostView.nhn?blogId=qbxlvnf11&logNo=221566232632&categoryNo=75&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView