NLP 이해하기
업데이트:
NLP(Natural Language Processing) 자연어 처리
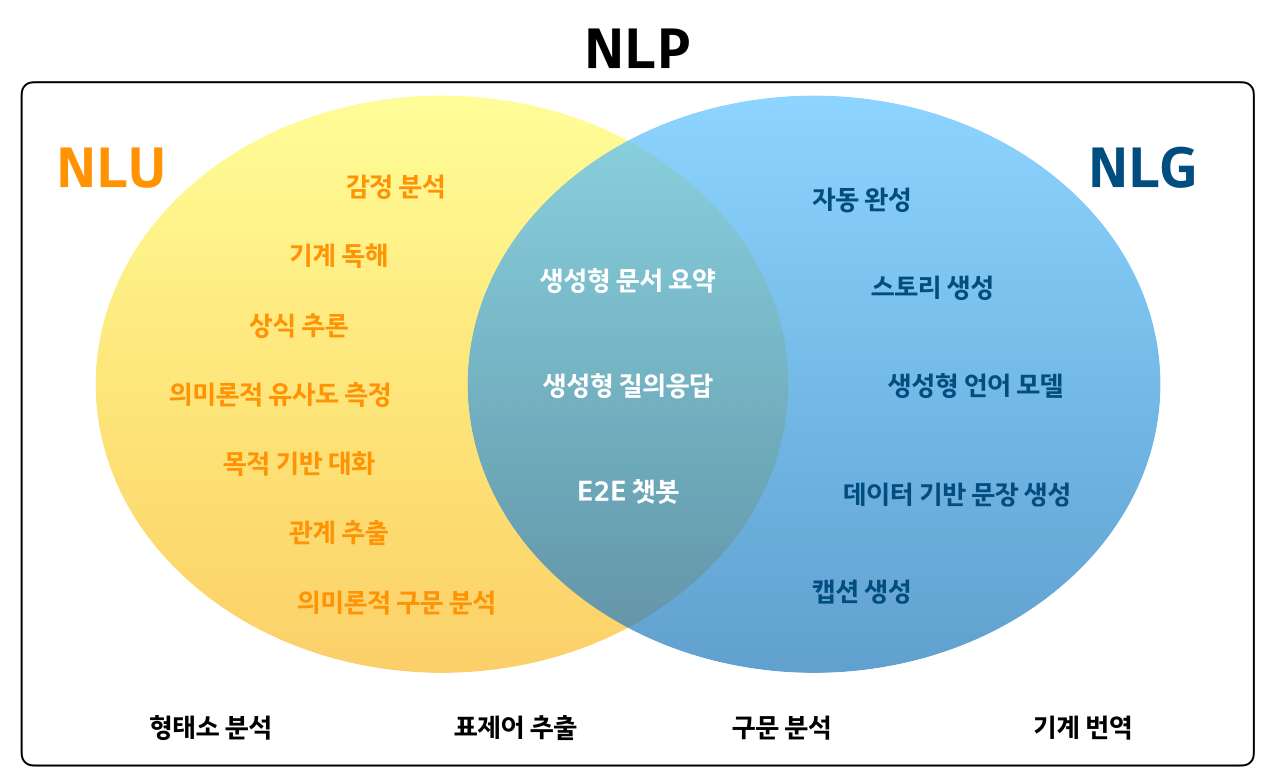
- NLU(Natural Language Understanding) 자연어 이해 : 자연어 형태의 문장을 이해하는 기술
- 사람-기계 상호작용이 필수인 경우 NLU는 핵심 기술
- ex) 구글에서 NLU 기술을 접목해 기존 키워드 매칭 방식과 비교해 더 나은 검색 서비스를 제공함. (BERT 정리)
- NLG(Natural Language Generation) 자연어 생성 : 자연어 문장을 생성하는 기술
- NLU와 NLG는 사람-기계, 기계-기계 사이 사람이 자연어로 소통하는 데 필요한 기술
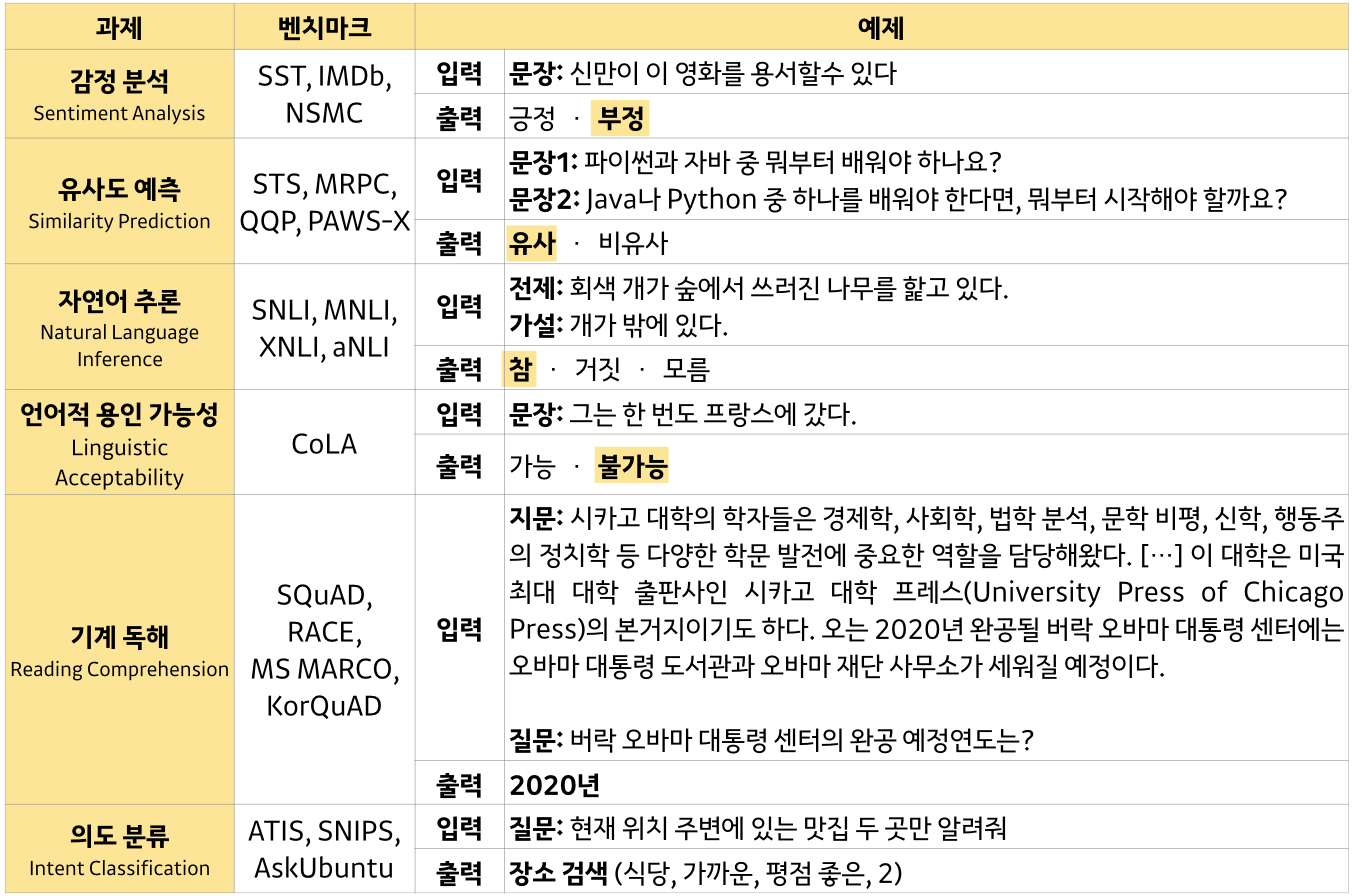
Language Model (LM)
언어 모델 성능 평가 (dataset)
GLUE : General Language Understanding Evaluation
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
https://gluebenchmark.com/
-
사전 학습된 딥러닝 기반 언어 모델인 ELMo, GPT-1, BERT 모두 GLUE 벤치마크에서 당시 최고의 성능을 보임
-
baseline : BiLSTM
-
dataset (9)
- single-sentence tasks
- CoLA (Corpus of Linguistic Acceptability)
- SST-2 (Stanford Sentiment Treebank)
- similarity and paraphrase tasks
- MRPC (Microsoft Research Paraphrase Corpus)
- QQP (Quora Question Pairs)
- STS-B (Semantic Textual Similarity Benchmark)
- inference tasks
- MNLI (Multi-Genre Natural Language Inference)
- QNLI (Question Natural Language Inference)
- RTE (Recognizing Textual Entailment)
- WNLI (Winograd Natural Language Inference)
- single-sentence tasks
| corpus | task | metrics | label | size (train/dev/test) |
|---|---|---|---|---|
| CoLA | acceptability | Matthews corr. | acceptable / not acceptable | 10K / 1K / 1.1K |
| SST-2 | sentiment | acc. | positive / negative | 67K / 872 / 1.8K |
| MRPC | paraphrase | acc. / F1 | same / not same | 1.7K / 408 / 3.6K |
| QQP | paraphrase | acc. / F1 | same / not same | 400K / - / 391K |
| STS-B | sentence similarity | Pearson/Spearman corr. | 1 ~ 5 (similarity score) | 7K / 1.5K / 1.4K |
| MNLI | NLI | metched acc. / mismatched acc. | entailment / contradiction / neutral | 393K / 20K / 20K |
| QNLI | QA/NLI | acc. | entailment / not entailment | ? 105K / 5463 / |
| RTE | NLI | acc. | entailment / not entailment | 2.7K / - / 3K |
| WNLI | coreference/NLI | acc. | 706 / - / 146 |
SuperGLUE
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
https://super.gluebenchmark.com/
-
GLUE보다 더 어려운 NLU 과제를 모은 벤치마크
-
baseline : BERT
-
dataset (8)
- BoolQ (Boolean Questions)
- CB (CommitmentBank)
- COPA (Choice of Plausible Alternatives)
- MultiRC (Multi-Sentence Reading Comprehension)
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
- RTE (Recognizing Textual Entailment)
- WiC (Word-in-Context)
- WSC (Winograd Schema Challenge)
| corpus | task | metrics | label | size (train/dev/test) | text sources |
|---|---|---|---|---|---|
| BoolQ | QA | acc. | yes / no | 9427 / 3270 / 3245 | Google queries, Wikipedia |
| CB | NLI | acc. / F1 | true / false / unknown | 250 / 57 / 250 | various |
| COPA | QA | acc. | 2 choices (correct cause/effect) | 400 / 100 / 500 | blogs, photography encyclopedia |
| MultiRC | QA | F1a / EM | true / false | 5100 / 953 / 1800 | various |
| ReCoRD | QA | F1 / EM | 주어진 entities 리스트에서 예측 | 101K / 10K / 10K | news (CNN, Daily Mail) |
| RTE | NLI | acc. | entailment / not entailment | 2500 / 278 / 300 | news, Wikipedia |
| WiC | WSD | acc. | true / false | 6000 / 638 / 1400 | WordNet, VerbNet, Wiktionary |
| WSC | coref. | acc. | true / false | 554 / 104 / 146 | fiction books |
* EM : exact match
SQuAD (Stanford Question Answering Dataset)
https://rajpurkar.github.io/SQuAD-explorer/
Machine Reading Comprehension (기계 독해)
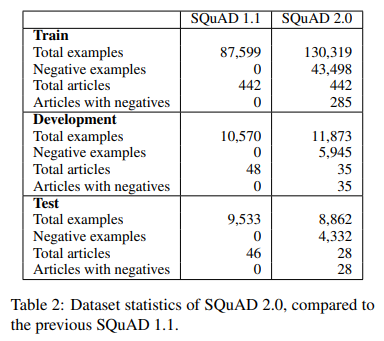
- SQuAD 2.0
- SQuAD 1.1 + 새로운 5만개 이상의 unanswerable questions
- unanswerable question은 온라인의 crowd worker(기계 아닌 진짜 사람)가 직접 생성하였다.
- 사람이 직접 했기 때문에 answerable question과 유사하여 기계적으로 판별이 어렵다.
- negative example : unanswerable question의 답
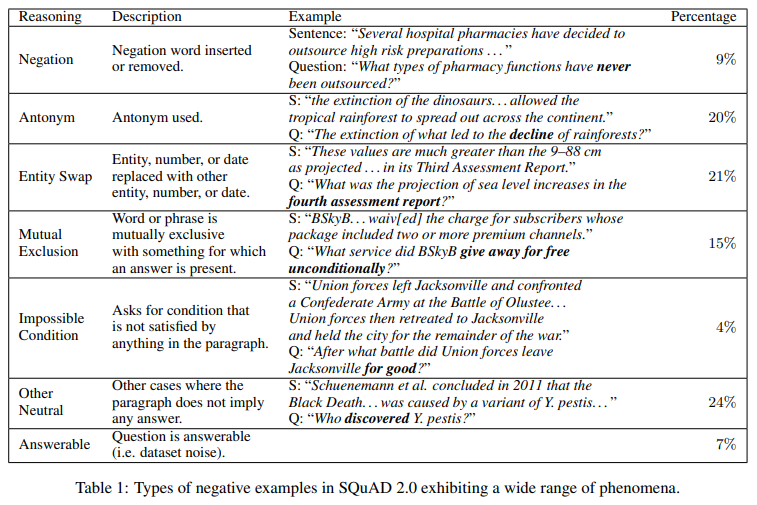
- SQuAD 1.1
NLI(Natural Language Inference) 자연어 추론
- Korean NLI
- MNLI (Multi-Genre Natural Language Inference)
- QNLI (Question Natural Language Inference)
- RTE (Recognizing Textual Entailment)
- SNLI(Stanford Natural Language Interence)
SNLI(Stanford Natural Language Interence) Corpus
https://nlp.stanford.edu/projects/snli/
| Text | Judgments | Hypothesis |
|---|---|---|
| A man inspects the uniform of a figure in some East Asian country. | contradiction C C C C C |
The man is sleeping. |
| An older and younger man smiling. | neutral N N E N N |
Two men are smiling and laughing at the cats playing on the floor. |
| A black race car starts up in front of a crowd of people. | contradiction C C C C C |
A man is driving down a lonely road. |
| A soccer game with multiple males playing. | entailment E E E E E |
Some men are playing a sport. |
| A smiling costumed woman is holding an umbrella. | neutral N N E C N |
A happy woman in a fairy costume holds an umbrella. |
-
MNLI와 같은 포맷
-
사람들이 판단한 judgement를 바탕으로 가장 많이 나온 label을 global label로 채택하였다.
- label
- entailment : premise가 hypothesis를 포함하는지
- contradiction : premise가 hypothesis와 모순되는지
- neutral : 그 외
- state-of-the-art : SemBERT (91.9%) (20.07.14 기준)
SRL(Semantic Role Labeling) 의미역 결정
https://cs.kangwon.ac.kr/~leeck/NLP/SRL.pdf
Text Augmentation
https://towardsdatascience.com/data-augmentation-in-nlp-2801a34dfc28
- Theaurus 유의어 사전
- replacing words/phrases with their synonyms(동의어)
- 단어 선택 -> geometric distribution에 의해 synonyms로 대체
- Word Embeddings
- 유사한 대체 언어 찾기 위해 KNN 또는 cosine similarity 사용
- pre-trained classic word embeddings 사용하여 유사성 검색 (Word2Vec, GloVe, fasttext)
- Back Translation
- 타겟 언어를 source 언어로 번역 -> 둘 모두 mix해서 train에 사용
- Contextualized Word Embeddings
- static word embeddings가 아닌 target word 대체를 위해 contextualized word embeddings 사용
- TDA(Translation Data Augmentation)
- contextual augmentation에서 bi-directional language model을 사용할 것을 제안함
- target word 선택 -> 주변 단어를 통해 가능한 replacement를 예측
- 타겟이 문장의 어느 위치에든 존재할 수 있으므로, 양방향 구조를 통해 학습
- CNN, RNN을 통해 language model approach를 검증했고 긍정적임
- Text Generation
- 몇 단어를 replace하는 것이 아니라 전체 문장을 생성
- pre-defined quetion을 사용하는 template augmentation : rule-based quetion을 사용하여 template questions과 쌍을 이루는 answer를 생성
- image feature을 제공하여 질문 생성하기 위해 LSTM 활용
- 몇 단어를 replace하는 것이 아니라 전체 문장을 생성
EDA (Easy Data Augmentation)
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- SR (Synonym Replacement) : 유의어 대체
- RI (Random Insertion) : 임의의 단어 삽입
- RS (Random Swap) : 두 단어 위치 바꿈
- RD (Random Deletion) : 임의의 단어 삭제
| operation | sentence |
|---|---|
| None | A sad, superior human comedy played out on the back roads of life. |
| SR | A lamentable, superior human comedy played out on the backward road of life. |
| RI | A sad, superior human comedy played out on funniness the back roads of life. |
| RS | A sad, superior human comedy played out on roads back the of life. |
| RD | A sad, superior human out on the roads of life. |
limitation
- 데이터가 충분하다면 성능 향상 미미할 수 있음
- pretrained model을 사용한 경우 상당한 개선 효과를 거두지 못할 수 있음
참조