NLI dataset biases
업데이트:
NLI dataset biases에 관하여 정리한 글입니다.
| dataset | type |
|---|---|
| Diagnostics | commonsense knowledge / logical reasoning / predicate-argument structures / lexical semantics |
| HANS | lexical overlap / subsequence / constituent |
| Stress | competence / distraction / noise |
관련 논문
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference
Adversarial Filters of Dataset Biases
https://arxiv.org/abs/1810.09774
https://arxiv.org/pdf/1909.08940.pdf
https://arxiv.org/pdf/2003.02756.pdf
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9031510
GLUE : General Language Understanding Evaluation
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
dataset : https://gluebenchmark.com/
-
사전 학습된 딥러닝 기반 언어 모델인 ELMo, GPT-1, BERT 모두 GLUE 벤치마크에서 당시 최고의 성능을 보임
-
baseline : BiLSTM
-
dataset (9)
- single-sentence tasks
- CoLA (Corpus of Linguistic Acceptability)
- SST-2 (Stanford Sentiment Treebank)
- similarity and paraphrase tasks
- MRPC (Microsoft Research Paraphrase Corpus)
- QQP (Quora Question Pairs)
- STS-B (Semantic Textual Similarity Benchmark)
- inference tasks
- MNLI (Multi-Genre Natural Language Inference)
- QNLI (Question Natural Language Inference)
- RTE (Recognizing Textual Entailment)
- WNLI (Winograd Natural Language Inference)
- single-sentence tasks
NLI(Natural Language Interence) dataset
SNLI(Stanford Natural Language Interence) Corpus [GLUE x]
dataset : https://nlp.stanford.edu/projects/snli/
-
MNLI와 같은 포맷
- label
- entailment : premise가 hypothesis를 포함하는지
- contradiction : premise가 hypothesis와 모순되는지
- neutral : 그 외
- state-of-the-art : SemBERT (91.9%) (20.07.14 기준)
MNLI (Multi-Genre Natural Language Inference)
- crowd-sourced collection of sentence pairs with textual entailment annotations
- premise sentences는 10개의 다른 출처로부터 수집된다. (transcribed speech, fiction, government reports)
- test set은 authors로부터 label을 받아 matched(in-domain)과 mismatched(cross-domain) 모든 sections에서 evaluate 한다.
-
SNLI training dataset(550k)를 보조로 사용하며 추천한다.
- label
- entailment : premise가 hypothesis를 포함하는지
- contradiction : premise가 hypothesis와 모순되는지
- neutral : 그 외
QNLI (Question Natural Language Inference)
- question-paragraph pairs로 구성된 question-answering dataset
- (Wikipedia에서 인용한) paragraph의 문장 하나가 해당 질문에 대한 답을 포함하고 있다.
- sentence pair classification으로 convert
- 각 question과 sentence를 하나의 pair로 구성하고, question과 context sentence 사이 low lexical overlap(어휘적 중첩)으로 pairs를 filter out한다.
- context sentence가 question에 대한 answer를 포함하고 있는지 여부를 결정한다.
- 정확한 답을 선택해야 하는 요건을 없앴지만, 또한 답이 항상 input에 나타나고 lexical overlap이 reliable que라는 simplifying assumptions를 없앴다.
- label
- entailment
- not entailment
Diagnostic Data [NLI]
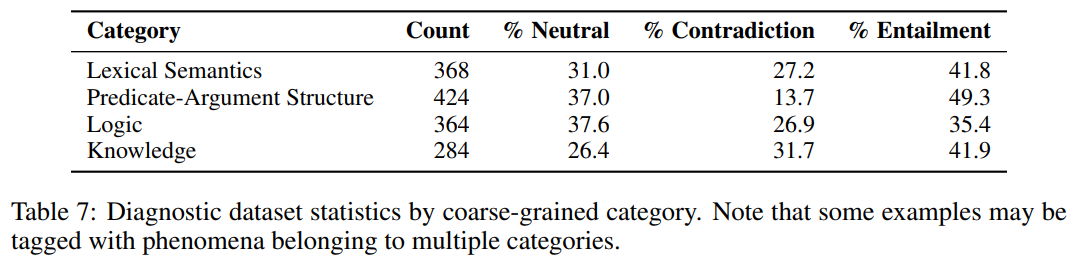
dataset은 word meaning, sentence structure에서부터 high-level reasoning(추론), word knowledge 응용에 이르기까지 NLU의 많은 수준을 분석할 수 있도록 설계되었다. 이러한 종류의 분석을 실현하기 위해, 먼저 네가지 광범위한 categories of phenomena로 구분하였다. 이러한 categories는 liguistic phenomena and entailment를 이해하기 위해 사용된 하나의 렌즈일 뿐이며, categories는 특정 언어 이론에 근거한 것이 아니라 언어학자들이 syntax와 semantics 연구에서 자주 식별하고 모델링하는 issue에 근거하고 있다.
dataset은 benchmark가 아니라 (error anlysis, qualitive model comparison, development of adversarial examples에 도움이 될 수 있는) analysis tool로써 제공된다.
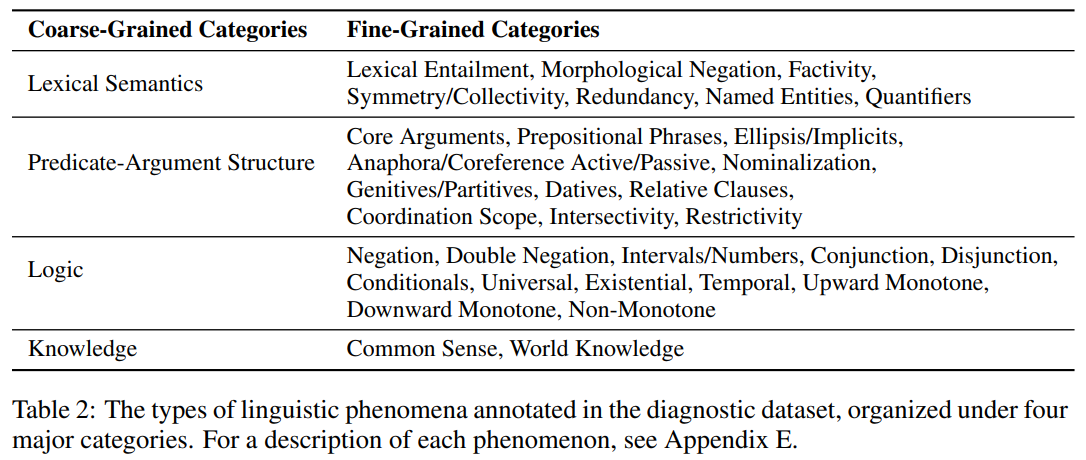
- Lexical Semantics
- Predicate-Argument Structure
- Logic
- Knowledge
HANS : Heuristics Analysis fo Natural language inference Systems
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference 논문을 정리한 글입니다.
github : https://github.com/tommccoy1/hans
paper
abstract
MNLI에서 학습한 BERT 모델의 경우 HANS에서 매우 낮은 성능을 보이는 것을 발견하였다. 본 논문에서는 NLI system을 개선할 수 있는 상당한 여지가 있으며, HANS dataset가 이러한 영역에서 동기를 부여하며 측정할 수 있다고 이야기한다.
contributions
-
HANS dataset : NLI 모델이 학습할 가능성이 높은 잘못된 heuristics에 대한 특정 가설을 테스트하는 NLI evaluation set
- MNLI에서 훈련된 state-of-the-art models의 interpretable shortcomings를 밝히기 위해 HANS dataset 사용 : 이러한 단점은 아래에서 발생할 수 있다.
- inappropriate model inductive biases
- insufficient signal by training datasets
- or both
- 이러한 단점들이 HANS에 존재하는 사례의 종류로 training set을 augmentation함으로써 이러한 단점들이 덜해지는 것을 보여준다.
conclusions
기존의 네 가지 NLI 모델이 HANS에서 매우 저조한 성능을 보인다는 것을 발견했는데, 이는 NLI test set의 높은 정확도가 언어에 대한 깊은 이해보다는 잘못된 heuristics 이용 때문이라는 것을 시사한다.
standard evaluations에 대한 state-of-the-art models의 인상적인 정확성에도 불구하고 여전히 많은 진전이 이뤄져야 하며, HANS와 같이 chellenging dataset가 모델이 배우고자 하는 것을 배우는지를 결정하는 데 중요하다는 것을 보여준다.
Natural Language Inference(NLI) system
NLI는 premise(A)에 대해 hypothesis(B)가 true(entailment)인지, false(contradiction)인지, undetermined(neutral)인지 판단한다.
syntatic heuristics

-
hierarchy : constituent heuristic < subsequence heuristic < lexical overlap heuristic
-
standard NLI training datasets(SNLI, MNLI)에 대해 train하는 statistical learner가 heuristics를 채택할 두가지 이유
- MNLI training set에는 heuristics에 해당하는 examples이 아닌 것보다 더 많이 포함되어 있다.
- input representations가 heuristics에 취약하게 만들 수 있다.
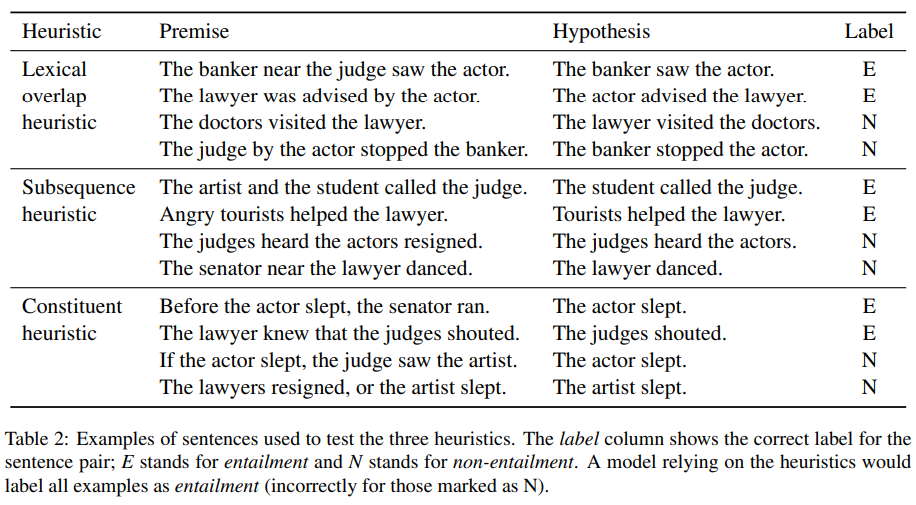
1) Lexical Overlap heuristic
2) Subsequence heuristic
3) Constituent heuristic
Stress Test
Stress Test Evaluation for Natural Language Inference 논문을 참고하였습니다.
github blog : https://abhilasharavichander.github.io/NLI_StressTest/
Weakness of state-of-the-art NLI
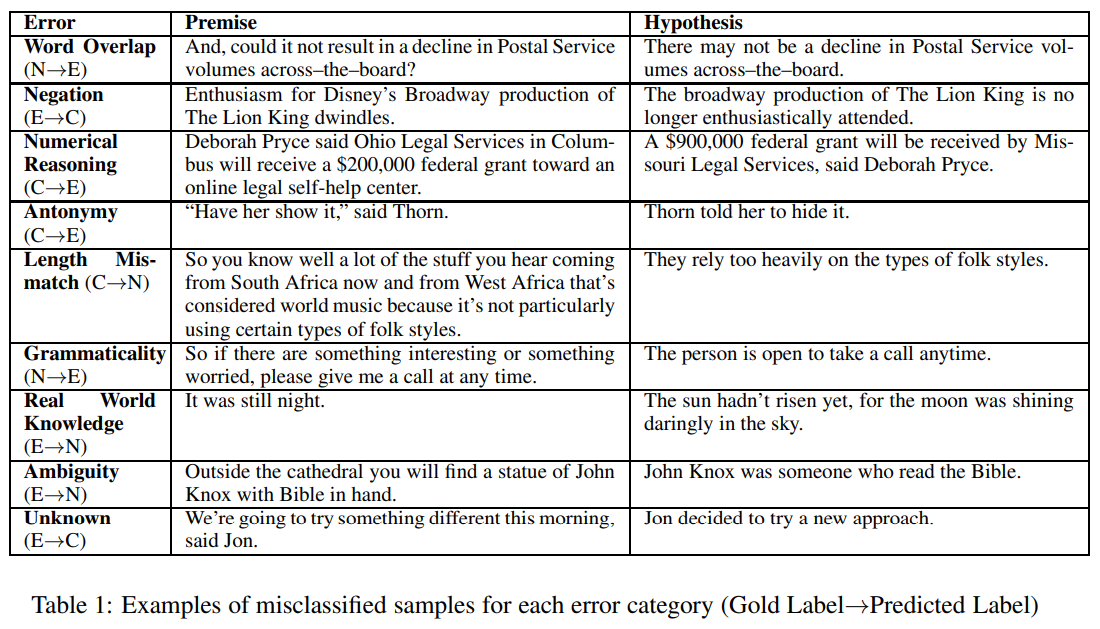
- Word Overlap (29%) : premise와 hypothesis 사이에 large word-overlap이 존재하면, 관련이 없더라도 잘못된 entailment 예측을 할 수 있다. very little word-overlap의 경우, entailment 대신 neutral을 예측할 수 있다.
- Negation (13%) : 강한 부정 단어(no, not)은 neutral/entailment를 contradiction으로 예측하게 한다.
- Antonymy (5%) : 반의어가 들어 있는 premise-hypothesis pairs는 contradiction으로 감지되지 않는다.
- Numerical Reasoning (4%) : 일부 premise-hypothesis pairs에 대해 모델은 numbers/quantifiers를 포함하는 추론을 정확한 relation predict에 대해 수행할 수 없다.
- Length Mismatch (3%) : premise가 hypothesis보다 훨씬 더 긴 경우, extra information이 모델의 주의를 산만하게 할 수 있다.
- Grammaticality (3%) : spelling errors 또는 incorrect subject-verb agreement가 잘못되어 premise/hypothesis가 잘못 형성된 경우
- Real-World Knowledge (12%) : real-word knowledge가 없으면 classify하기 어려운 경우
- Ambiguity (6%) : 정답이 불분명한 경우. 가장 어려운 경우.
- Unknown (26%) : 명백한 오류의 원인이 식별되지 않는 경우.
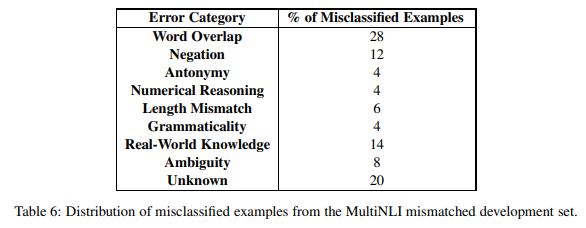
Stress Test Set Construction
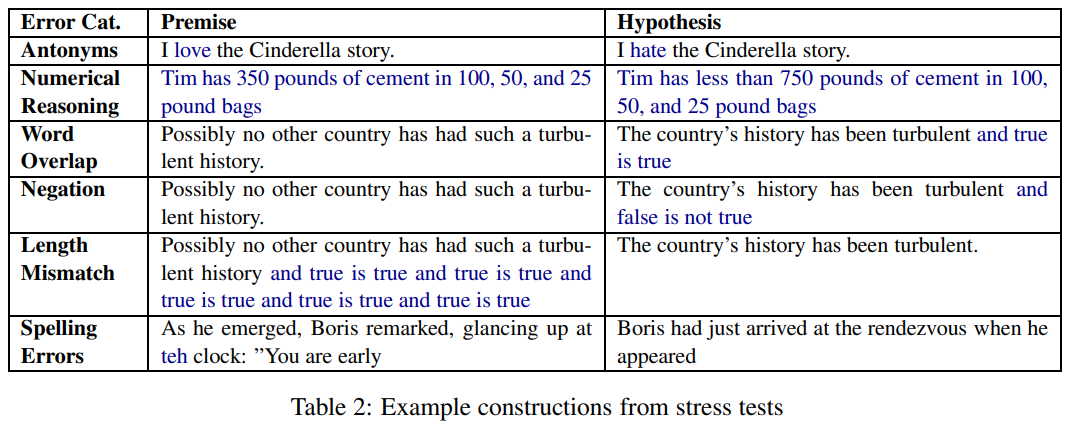
Competence test
- antonym (m/mm)
- numerical reasoning
Distraction test
- word overlap (m/mm)
- negation (m/mm)
- length mismatch (m/mm)
Noise test
- spelling error (m/mm)
Stress Test Evaluation of Transformer-based Models in Natural Language Understanding Tasks (paper)
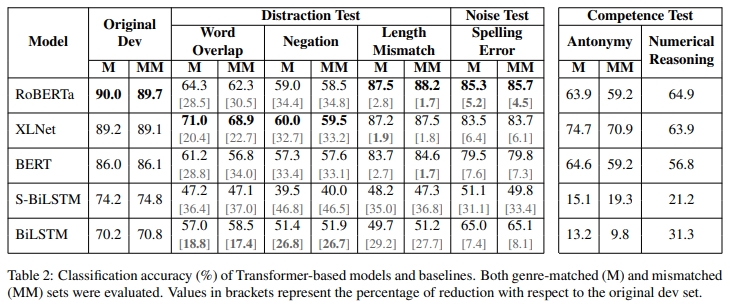
models performance on Distribution Test
두가지 방법으로 robustness를 확인할 수 있다.
models performance on Noise Test
models performance on Competence Test
AFLITE : Lightweight Adversarial Filtering
Adversarial Filters of Dataset Biases 논문을 정리한 글입니다.
WINOGRANDE: An Adversarial Winograd Schema Challenge at Scale이 실제로 AFLITE에 대해 처음 소개한 논문이고, Adversarial Filters of Dataset Biases는 dataset biases를 바탕으로 연구한 논문이다.
paper
abstract
large neural model은 language & vision benchmarks에서 human-level performance를 입증하였지만, 그들의 performance는 adversarial 또는 out-of-distribution samples에서 상당히 낮다. 이는 이러한 모델이 spurious dataset biases(편향)에 overfitting하여 기본 작업이 아닌 dataset을 해결하는 방법을 배웠는지에 대한 의문을 제기한다.
본 논문은 최근 제안된 approach인 AFLITE를 조사하였다. AFLITE는 machine performance의 overestimation을 완화하기 위해 이러한 dataset biases를 adversarially filter한다. optimum bias reduction을 위해 genralized framework에 배치함으로써 AFLITE에 대한 이론적 이해를 제공한다. 우리는 AFLITE가 reduction of measurable dataset biases에 광범위하게 적용가능하며 filtered datasets에 대해 훈련된 모델이 out-of-distribution tasks에 더 나은 generalization을 제공한다는 광범위한 근거 자료를 제시한다.
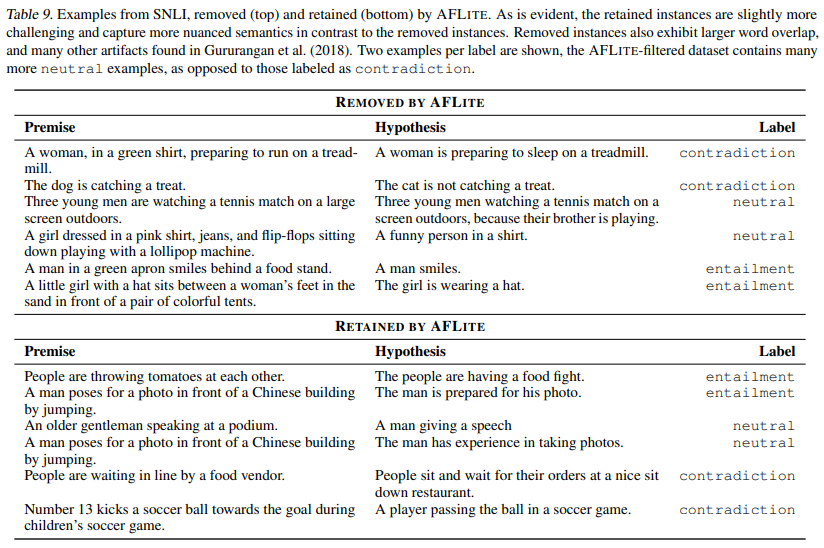
마지막으로 filtering 결과 model performance는 large drop(SNLI에서 92% -> 62%) 결과를 보이지만, human performance는 높게 유지된다. 우리의 연구는 filtered dataset이 upgraded benchmarks 역할을 수행함으로써 robust genreralization을 위한 새로운 연구 과제를 제기할 수 있다는 것을 보여준다.
conclusion
정확한 benchmark estimation을 위해 data에서 spurious biases(거짓 편향)를 adversarially filter하는 iterative greedy algorithm인 AFLITE에 대해 deep-dive를 보였다. AFLITE를 지원하는 theoretical framework를 제공하고 광범위한 분석을 제공하면서 synthetic and real datasets에 대한 bias reduction 효과를 보여준다.
NLI out-of-distribution Benchmarks
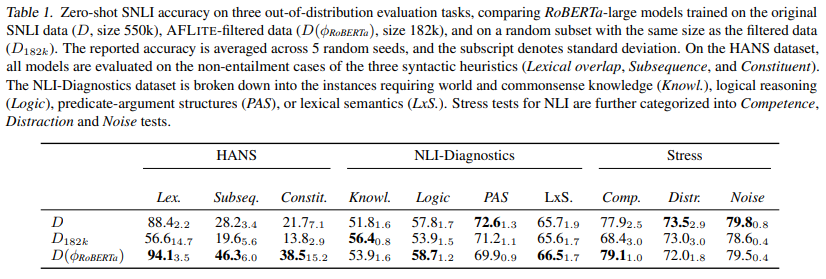
HANS
NLI Diagnostics
Stress tests for NLI
Stress test evaluation for natural language inference.
Adversarial NLI
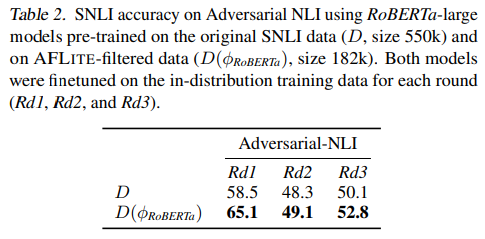
Adversarial NLI: A new benchmark for natural language understanding
AFLITE algorithm