BERT 및 응용 모델 이해하기 - BERT, RoBERTa, ALBERT
업데이트:
BERT : Bidirectional Encoder Representations from Transformers
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문을 참고하였습니다.
- 18년 10월 공개한 구글의 새로운 language representation model
- NLP 11개의 task에서 최고 성능을 보임
2 model size for BERT
- BERT-BASE
- BERT-LARGE
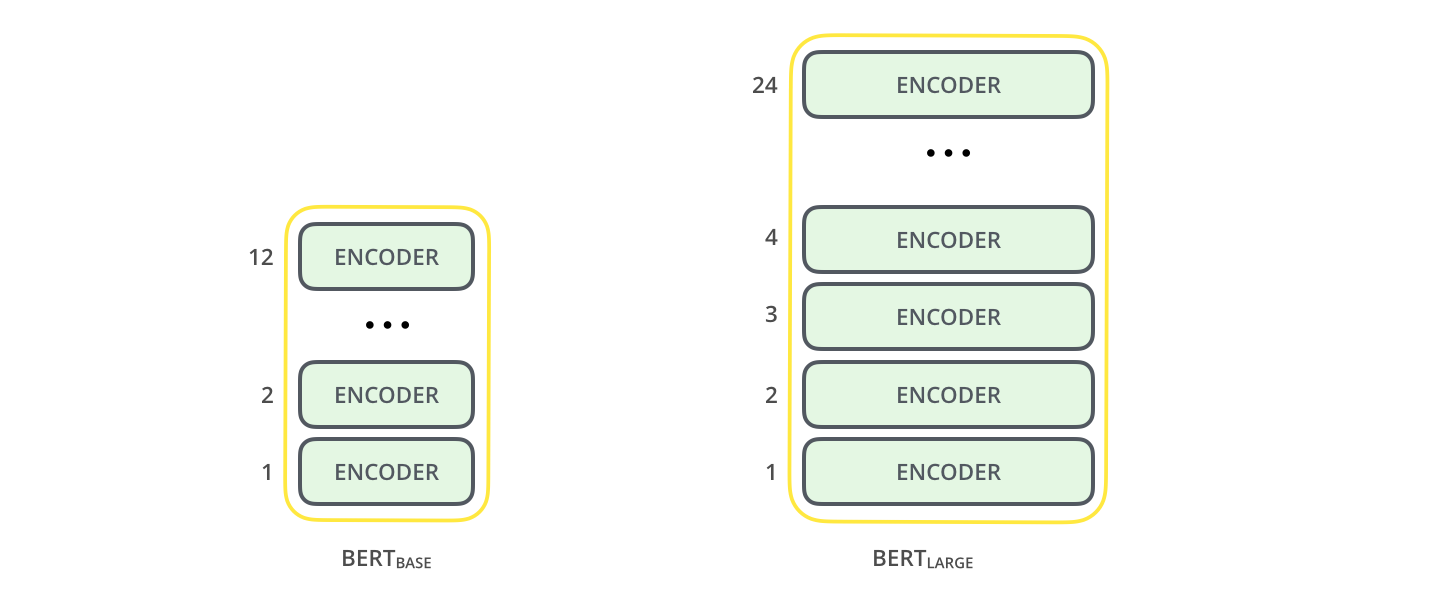
model
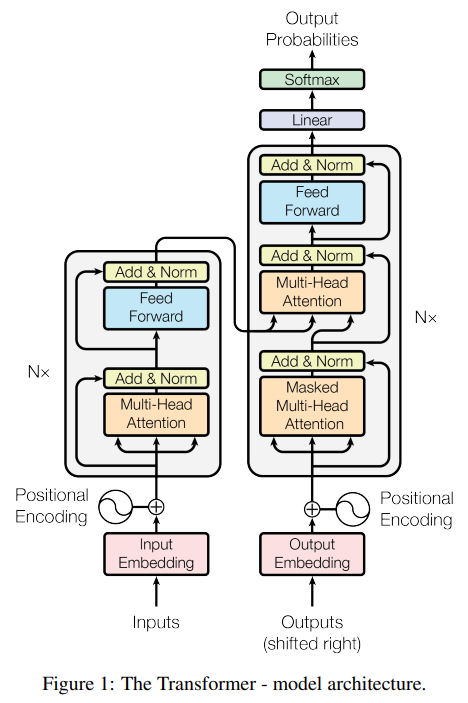
BERT의 모델은 Transformer 기반으로 하며, BERT는 그림에서 왼쪽 encoder만 사용하는 모델이다.
Input Embedding
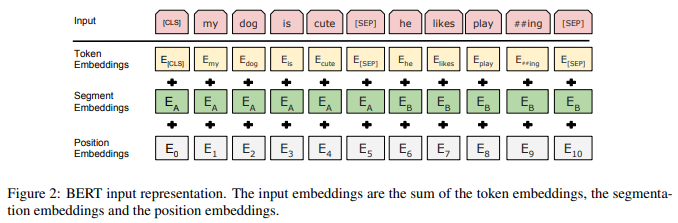
아래 세가지 embedding을 합하여 하나의 embedding으로 만든 후, layer normalization 그리고 dropout을 적용하여 input으로 사용한다.
1. Token Embeddings
30,000 token vacabulary와 함께 WordPiece embeddings를 사용하였다. 흔히 사용하는 word embedding 방식을 사용하지 않았다. 모든 sequence의 첫번째 token은 항상 [CLS]이다. 두 문장은 [SEP]를 통해 구분한다.
2. Segment Embeddings
[SEP]를 기준으로 두 문장을 구분한다.
3. Position Embeddings
self-attention은 입력 위치는 고려하지 못하였다. 위치 정보를 넣어 주어 준다.
Encoder Block
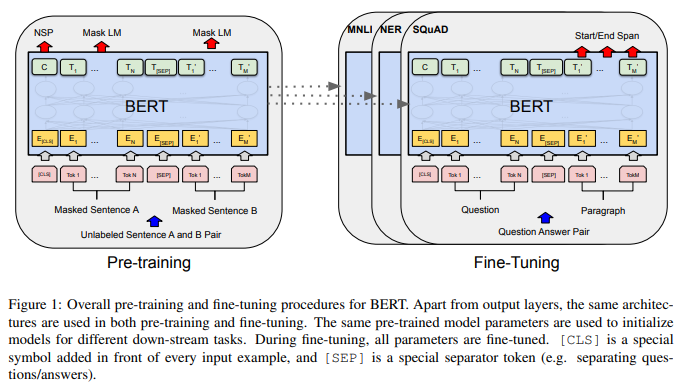
Pre-Training
- 사전학습
- unsupervised learning
- general-purpose language understanding 모델 구축
기존의 left-to-right 또는 right-to-left language model을 사용하지 않았다. 두가지 unsupervised tasks를 사용하여 pre-train 하였다.
task #1 : Masked LM (MLM)
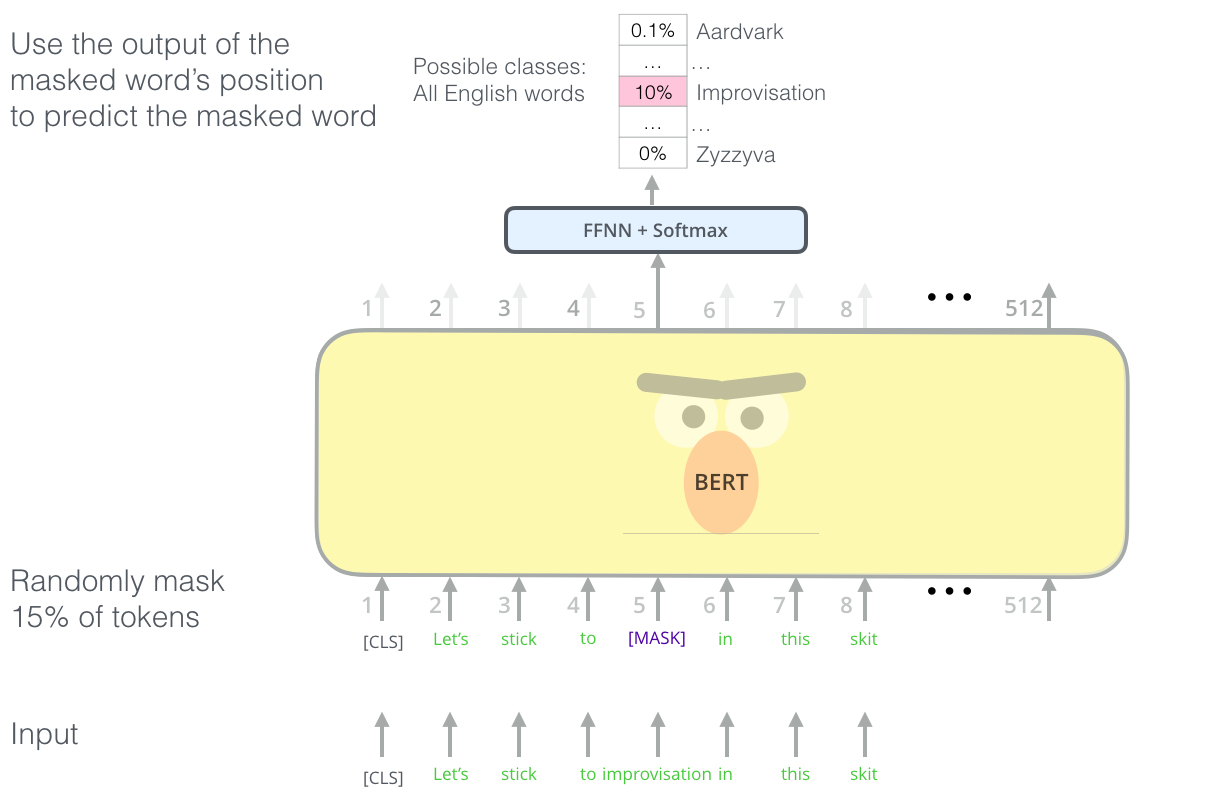
입력에서 token 하나를 가리고(mask) 해당 token을 맞추는 Language Model(LM)
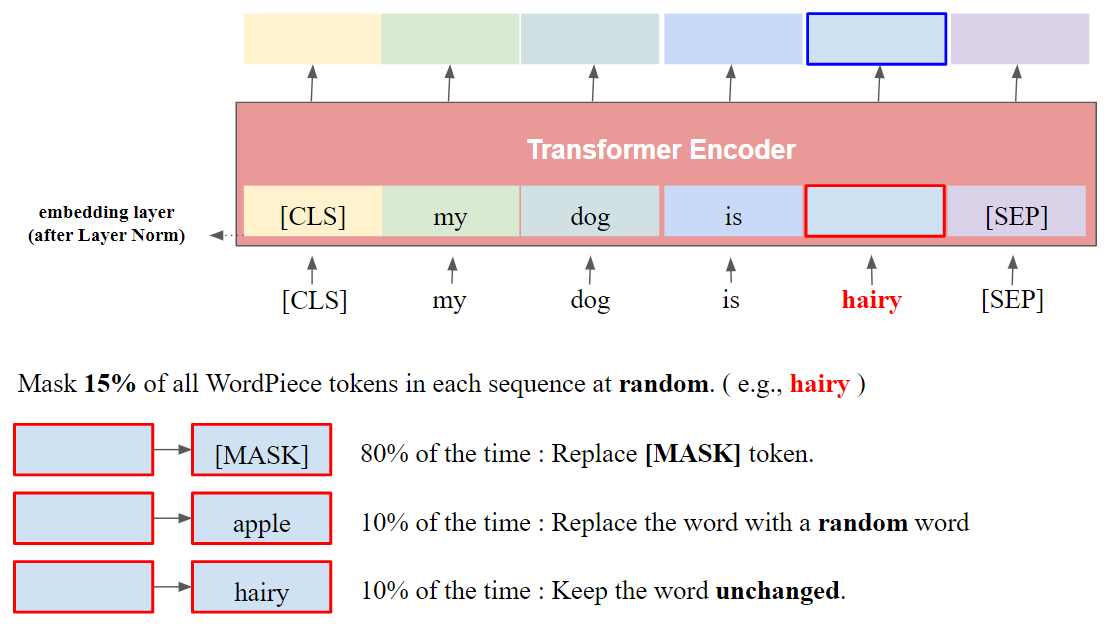
모든 WordPiece tokens의 15%를 [MASK] token으로 바꾼다.
- 80% of time : [MASK] token 변경
- 10% of time : random word 변경
- 10% of time : 변경 x
task #2 : Next Sentence Prediction (NSP)

두 문장에 대해 두번째 문장이 첫번째 문장 바로 다음에 오는 문장인지 예측하여 문맥과 순서를 학습할 수 있다. 두 문장은 [SEP] token으로 구분한다.
input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
output = IsNext
input = [CLS] the man [MASK] to the strore [SEP]
penguin [MASK] are flight ##less birds [SEP]
output = NotNext
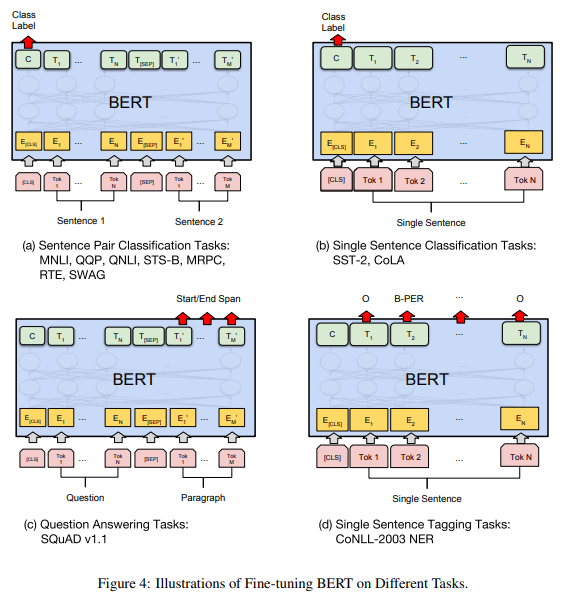
Fine-Tuning
- 미세조정
- supervised learning
- downstream NLP task(QA, STS 등)에 적용하는 semi-supervised learning 모델
위에서 pre-train한 parameter로 초기화하여 parameter를 fine-tuning 한다.
RoBERTa : Robustly optimized BERT Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach 논문을 참고하였습니다.
BERT와 다른 점
- large-scale text copora dataset
- dynamic masking
- model input format and next sentence
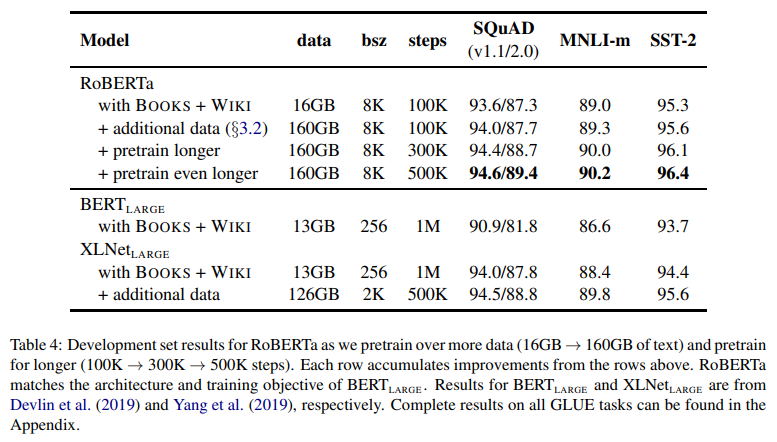
additional data [total 160GB]
- RoBERTa ) 많은 data, 큰 batch
- BookCorpus + (english) Wikipedia [16GB]
- original data used to train BERT
- CC-News [+76GB]
- collected from English portion of the CommonCrawl News dataset
- contain 63million English news articles (2016.09 ~ 2019.02)
- 76GB after filtering
- OpenWebText [+38GB]
- open-source recreation of the WebText corpus described in Radford et al.
- text is web content extracted from URLs shared on Reddit with at least three upvotes
- Stories [+31GB]
- introduced in Trinh and Le containing a subset of CommonCrawl data filtered to match the story-like style of Winograd schemes
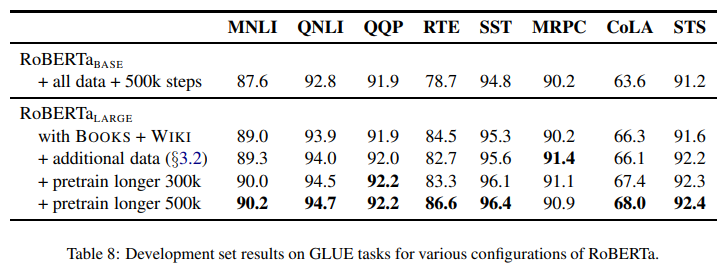
pretrain longer
Static vs. Dynamic Masking
- BERT ) static masking
- masking 한번 수행
- ???
- RoBERTa ) dynamic masking
- 매 epoch 각 training instance에서 같은 mask를 사용하는 것을 피하기 위해서
- epoch마다 다른 masking 사용
- data를 10개 복제하여 각 sequence가 40 epoch에 걸쳐 10가지 방법으로 masking되도록 처리
- 학습 중 동일한 mask는 4번만 보게 된다.
Model Input Format & Next Sequence Prediction(NSP)
- BERT ) NSP
- BERT의 pre-train에서 NSP loss를 통해 train한다.
- BERT 논문에서는 NSP를 제거하면 QNLI, MNLI, SQuAD 1.1에서 성능이 저하된다고 하였다.
- 최근 연구에서는 NSP loss의 필요성에 대해 의문을 제기하였다.
- RoBERTa ) None, NSP 제거
- training input format
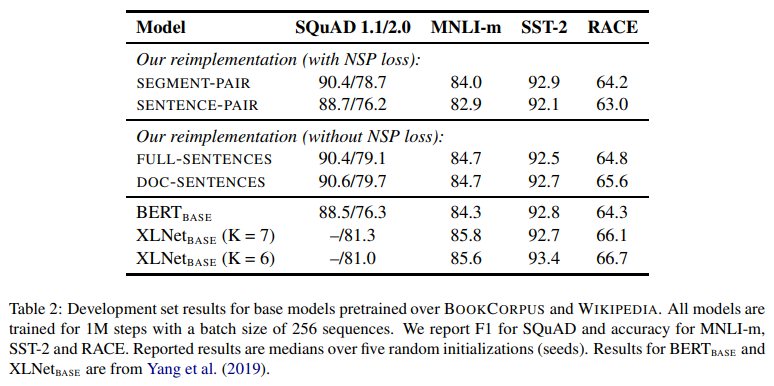
- SEGMENT-PAIR+NSP (BERT와 동일)
- original input format used in BERT with NSP loss
- input = pair of segments = multiple natural sentences
- total combined length = less than 512 tokens
- SENTENCE-PAIR+NSP
- input = pair of natural setences
- total length = less than 512 tokens
- batch size 크게 (SEGMENT-PAIR+NSP와 유사한 total tokens를 유지할 수 있도록)
- retrain NSP loss
- FULL-SENTENCES
- input = packed with full sentences
- total length = at most 512 tokens
- NSP loss 제거
- DOC-SENTENCES
- input = FULL-SENTENCES와 비슷
- 512 tokens
- batch size 크게 (FULL-SENTENCES와 유사한 total tokens를 유지할 수 있도록)
- NSP loss 제거
training with Large Batches
Text Encoding (실험 진행 안함)
- OpenGPT2의 BPE는 유니코드 문자 대신 byte를 기본 하위 단위로 하는 BPE를 사용한다.
- 이를 사용하면 “unknown” token 없이도 input text를 encoding할 수 있는 적당한 크기의 하위 단어 어휘를 train할 수 있다.
- encoding에 대한 실험은 future work로…
ALBERT : A Lite BERT
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations 논문을 참고하였습니다.
github : https://github.com/google-research/albert
BERT 문제
- memory limitation
- training time
- memory degradation
model
BERT 모델의 크기는 줄이고 성능은 높임.
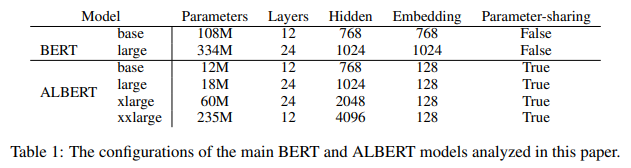
factorized embedding parameterization
input token embedding size (E) , hidden size (H)
-
BERT, XLNet, RoBERTa ) E = H
-
ALBERT ) E < H
cross-layer parameter sharing
-
BERT ) non-shared
-
ALBERT ) all-shared
- sharing parameters (ALBERT는 all parameters across layers)
- only sharing feed-forward network(FFN) parameters across layers
- only sharing attention parameters
- transformer layer간에 같은 parameter를 공유하며 사용하는 것
- recursive transformer (Universal Transformer에서도 각 layer가 parameter를 공유함)
- sharing parameters (ALBERT는 all parameters across layers)
inter-sentence coherence loss
- BERT ) Next Sentence Prediction(NSP)
- 두번째 문장이 첫번째 문장의 다음에 해당하는지 predict
- 학습 데이터 구성 시 두번째 문장은 positive example(실제 문장) 또는 negative example(임의의 문장)으로 처리한다.
- negative example은 첫번째 문장과 완전히 다른 topic의 문장일 확률이 높으므로 문장 간 연관곽녜를 학습하기보다 두 문장이 같은 topic에 대해 말하는지 판단하는 topic prediction에 가깝다.
-
XLNet , RoBERTa ) 사용 안함 (None)
- ALBERT ) Sentence Order Prediction(SOP)
- 실제로 연속하는 두 문장(positive example)과 두 문장의 순서를 앞뒤로 바꾼 것(negative example)으로 구성되어 문장의 순서가 옳은지 predict
Accuracy
GLUE (test set)
| model | CoLA | SST-2 | MNLI-m | MNLI-mm | QNLI | RTE | MRPC | QQP | STS-B |
|---|---|---|---|---|---|---|---|---|---|
| BERT (large) | 60.5 | 94.9 | 86.7 | 85.9 | 92.7 | 70.1 | 89.3 | 72.1 | 86.5 |
| RoBERTa | 67.8 | 96.7 | 90.8 | 90.2 | 98.9 | 88.2 | 92.3 | 90.2 | 92.2 |
| ALBERT | 69.1 | 97.1 | 91.3 | 99.2 | 89.2 | 93.4 | 90.5 | 92.5 |
참조
- BERT
http://jalammar.github.io/illustrated-bert/
https://keep-steady.tistory.com/19
http://docs.likejazz.com/bert/
https://blog.est.ai/2020/03/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%95%95%EC%B6%95-%EB%B0%A9%EB%B2%95%EB%A1%A0%EA%B3%BC-bert-%EC%95%95%EC%B6%95/
- RoBERTa
https://jeonsworld.github.io/NLP/roberta/
https://baekyeongmin.github.io/paper-review/roberta-review/
- ALBERT
https://y-rok.github.io/nlp/2019/10/23/albert.html
https://dos-tacos.github.io/paper%20review/google-albert/