SemBERT 이해하기 - Semantics-aware BERT for Language Understanding
업데이트:
Semantics-aware BERT for Language Understanding 논문을 정리한 글입니다.
abstract
최근 language representation 연구에서는 contextualized features를 language model training에 통합하여 다양한 기계 독해 및 NLI에 좋은 결과를 보였다. 하지만 기존 language representation 모델(ELMo, GPT, BERT 등)은 문자 또는 word embedding과 같은 plain context-sensitive features만 활용한다. 이러한 모델은 language representation에 풍부한 의미(seamantic)를 제공할 수 있는 structured semantic 정보를 통합하는 것을 거의 고려하지 않는다.
NLU를 증진시키기 위해…
- pre-trained semantic role labeling으로부터 explicit contextual semantics를 통합한다.
- BERT backbone에 걸쳐 contextual semantics을 명시적으로 흡수할 수 있는 향상된 language representation 모델인 Semantics-aware BERT(SemBERT)를 소개한다.
SemBERT는 상당한 작업별 수정 없이 BERT 전구체의 편리한 사용성을 light fine-tuning 방법으로 유지한다. BERT에 비해 SemBERT는 개념상 단순하지만 더욱 강력하다. 10가지 독해와 NLI 과제에서 새로운 최첨단 기술을 습득하거나 성과를 크게 향상시킨다.
introduction
현재의 NLU 모델은 불충분한 contextual semantic representation 및 learning으로 어려움을 겪고 있다. 실제로 NLU는 sentence contextual semantic analysis와 유사한 목적을 공유한다. 간단히 말해, 문장의 SRL(semantic role labeling)은 문장의 중심적 의미와 관련하여 who did what to whon, when, why를 발견하는 것으로 NLU의 과제 목표와 일치한다.
human language에서 문장은 보통 다양한 predicate-argument 구조를 포함하는 반면, neural model은 multiple semantic 구조를 모델링하는 것에 대해 거의 고려하지 않고 문장을 embedding representation으로 encoding 한다.
우리는 명시적인 contextual semantic 단서가 있는 fine-tuned BERT인 SemBERT를 제시함으로써 문장의 contextual semantics를 multiple predicate-specific argument 시퀀스에서 풍부하게 하고자 한다. 제안된 SemBERT는 fine-grained manner로 표현을 학습하며, 보다 깊은 의미 표현을 위한 plain context representation 그리고 explicit semantics에 대한 BERT의 장점을 모두 가진다.
우리 모델은 다음과 같은 세 가지 요소로 구성된다.
- out-of-shelf semantic role labeler : 다양한 semantic role label로 입력 문장에 주석을 달기 위함.
- sequence encoder : pre-trained language model을 사용하여 input raw text에 대한 표현을 작성하고 semantic role label이 병렬로 삽입되도록 매핑함.
- semantic integration component : text representation component를 contextual explicit semantic embedding과 통합하여 downstream tasks에 대한 joint representation을 얻음.
background & related work
Language Modeling for NLU
NLU(Natural Language Understanding)은 자연어에 대한 포괄적인 이해와 추론 능력이 필요하다. 최근 NLU 연구에서는 stacked attention mechanism 또는 large-scale corpus로 인해 모델이 점점 더 정교해져 계산 비용이 폭발적으로 증가한다.
distributed representations은 large-scale unlabeled text에서 단어의 local co-occurence를 캡처할 수 있기 때문에 NLP 모델의 standard part로 널리 사용되어 왔다. 하지만 이러한 접근 방식은 sentence level에서 contextual encoding을 고려하여 각 단어에 대해
본 논문에서는 context-sensitive features를 추출하는 방법을 따르고, explicit context semantics를 공동으로(jointly) 학습하기 위해 pre-trained BERT를 backbone encoder로 사용한다.
explicit contextual semantics
formal semantic frames
- FrameNet
- PropBank : computational linguistics에서 보다 대중적으로 구현됨
formal semantics(형식적인 의미론)은 일반적으로 semantic 관계를 predicate-argument 구조로 제시한다.
예를 들어, target verb (predicate) “sold” 일 때 모든 argument는 label이 다음과 같이 지정된다.
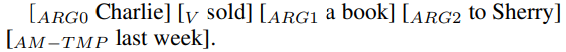
- \(ARG_0\) : agent, 판매자
- \(ARG_1\) : theme, 팔린 물건
- \(ARG_2\) : recipient, 구매자
- \(AM-TMP\) : adjunct indicating the timing of the action
- \(V\) : predicate, 술어
Semantic Role Labeling(의미역 결정) 참고 : http://air.changwon.ac.kr/?page_id=14
Semantic Role Labeling (SRL)
predicate-argument 구조를 parse하기 위한 NLP task
최근 end-to-end SRL system neural model이 소개되었다. 이 연구는 argument identification과 argument classification을 one-shot으로 다룬다. 최근에는 SRL을 쉽게 NLU에 통합할 수 있다.
https://web.stanford.edu/~jurafsky/slp3/20.pdf
https://web.stanford.edu/~jurafsky/slp3/slides/22_SRL.pdf
Semantics-aware BERT
자세한 내용은 BERT 참고
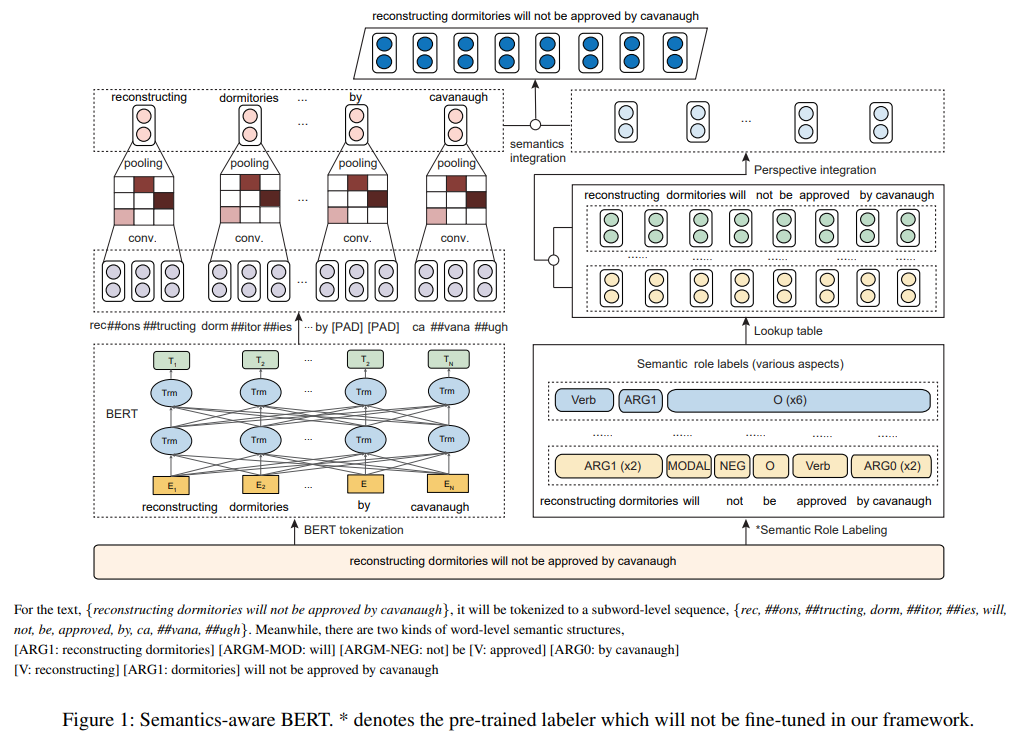
SemBERT는 multiple sequence inputs를 처리할 수 있도록 설계되었다.
- input sequence에 있는 단어들은 SRL(Semantic Role Labeler)로 전달되어 explicit semantics의 multiple predicate-derived 구조를 가져오고 해당 embeddings는 linear layer 이후에 집계되어 final semantic embedding을 형성한다.
- 여기서 embedding = lookup table
-
이와 병행하여, input sequence는 BERT word-piece tokenizer에 의해 subwords로 세분화되었다가 subword representation은 contextual word representation을 얻기 위해 convolution layer를 통해 word level로 다시 변환된다.
- 마지막으로, word representation과 semantic embedding이 결합되어 downstream tasks에 대한 joint representation을 형성한다.
Semantic Role Labeling
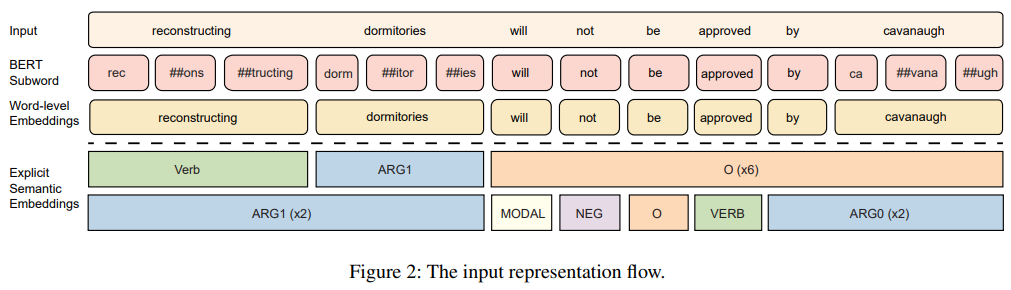
데이터 pre-processing 과정에서 각 문장은 pre-trained semantic labeler를 사용하여 여러 semantic sequences로 주석처리하였다. PropBank 스타일의 semantic roles로 모든 input sequence의 token에 semantic labels을 주석 처리하였다. 특정 문장이 주어지면, 다양한 predicate-argument 구조가 있을 것이다. 위의 그림(figure 2)에서 문장의 predicate(술어) 관점에서 두가지 semantic 구조를 가지는 것을 볼 수 있다.
multi-dimensional semantics를 공개하기 위해, semantic labels를 그룹화하고 다음 encoding component에서 text embeddings과 통합한다.
Encoding
raw text sequence와 semantic role label sequences는 먼저 pre-trained BERT를 feed 하기 위한 embedding vectors로 표현한다. input sequence인 \(X = {x_1, ... , x_n}\)은 길이가 n인 sequence of words로, 먼저 word pieces(subword tokens)로 tokenize 된다. 그런 다음, transformer encoder는 self-attention을 통해 각 token에 대한 contextual information을 capture 하고 sequence of contextual embeddings을 생성한다.
각 predicate와 관련된 \(m\) label sequences에 대해 \(T = \{t_1, ... , t_m\}\) 여기서 \(t_i\)는 \(n\) labels를 포함하며, \(\{label_1^i,~ ... ~,~ label_n^i\}\)로 표기한다. labels는 word-level이기 때문에 길이는 \(X\)의 원래 문장 길이인 \(n\)과 같다. semantic signals를 embeddings로 간주하고 lookup table을 사용하여 이러한 labels를 vector \(\{v_1^i, ... , v_n^i\}\)에 매핑하고 BiGRU layer(Bidirecional Gated Recurrent Unit)를 공급하여 latent space의 \(m\) label sequences에 대한 label representation을 얻는다.
\[e(t_i) = BiGRU (v_1^i, ... , v_n^i), ~ where ~ 0 < i ≤ m\]\(m\) label sequences에 대해 \(L_i\)는 token \(x_i\)에 대한 label sequences를 나타낸다.
\[e(L_i) = \{e(t_1), ... , e(t_m)\}\]label representation의 \(m\) sequences를 연결하고 그것들을 dimension d에서 joint representation을 얻기 위해 fully connected layer로 feed 한다.
\[e′(L_i) = W_2[e(t_1), ... , e(t_m)] + b_2 ~,\] \[e^t = \{e′(L_1), ... , e′(L_n)\}\] \[where ~ W_2, ~ b_2 : trainable ~ parameters\]Lookup Table (nn.Embedding)
pytorch의 nn.Embedding : https://wikidocs.net/64779
Intergration
intergration modules은 lexical text embedding과 label representations를 통합한다. 기존의 pre-trained BERT는 sequence of subwords을 기반으로 하는 반면, 소개된 semantic labels는 단어에 바탕을 두고 있기 때문에 서로 다른 크기의 sequences를 정렬할 필요가 있다. 따라서 각 단어에 대한 subwords를 분류하고 word-level의 representation을 얻기 위해 max pooling과 함께 CNN을 사용한다. 빠른 속도를 위해 CNN을 선택하였고 예비 실험은 (CNN에 의해 캡처된 local feature은 subword-derived LM modeling에 도움이 될 것이라고 생각하는) 관련 task에서 RNN 보다 더 나은 결과를 제공하는 것을 보여준다.
예 단어 \(x_i\)가 sequence of subwords \([s_1, ... , s_l]\)로 구성되어 있다고 가정하자. 여기서 \(l\)은 단어 \(x_i\)의 subwords 갯수이다. BERT의 subword \(s_j\)를 \(e(s_j)\)로 나타내며, 먼저 Conv1D layer를 활용한다.
\[e′_i = W_1 [e(s_i), e(s_{i+1}), ... , e(s_{i+k-1})] + b_1\] \[where~ W_1, b_1~ : ~ trainable~parabeters, k ~ : ~ kernel~size\]다음 ReLU와 max pooling을 \(x_i\)의 output embedding sequence에 적용한다.
\[e^*_i = ReLU(e_i), e(x_i) = MaxPooling(e^*_1, e^*_{l-k+1})\]따라서, word sequence \(X\)의 whole representation은 다음과 같이 표현된다.
\[e^w = \{e(x_1), ... , e(x_n)\} \in \mathbb{R}^{n*d_w}~,\] \[where~ d_w : dimension~of~word~embedding\]aligned context와 distilled semantic embeddings는 fusion function \(h~=~e^w \diamond e^t\) 에 의해 병합된다. 여기서 \(\diamond\)는 concatenation operation을 나타낸다. (summantion, multiplication, attention mechanisms를 시도했지만 concatenation이 가장 좋은 성능을 보임)
model implementation
SemBERT는 광범위한 작업에 대한 forepart encoder가 될 수 있으며 예측을 위한 linear layer만 있는 end-to-end model될 수도 있다. simplicity를 위해, fine-tuning 후 직접 예측을 제공하는 straigtforward SemBERT만 보여준다. (jointly training과 parameter sharing 없이 각 task에 대해 single model만 사용함)
Semantic Role Labeler
semantic labels를 얻기 위해 pre-trained SRL module을 사용하여 모든 pridicates와 해당 arguments를 한번에(one-shot) 예측한다. ELMo의 semantic role labeler를 구현하였고 CoNLL-2012의 English OntoNotes v5.0 benchmark dataset에서 F1 84.6%을 달성하였다. test time에는 BIO 제약조건을 사용하여 valid spans를 시행하기 위해 Viterbi decoding을 수행한다. 총 104 labels이 있으며 non-argument words는 \(O\), predicates는 \(Verb\) label을 사용한다.
Task-specific fine-tuning
Semantics-aware BERT에서는 semantics-aware BERT representation을 얻는 방법을 설명했다면, 여기서는 SemBERT를 classification, regression 및 span-based MRC tasks에 적용하는 방법을 보여준다.
fused contextual semantic 및 LM representations \(h\)를 lower dimension으로 변환하여 prediction distributions를 구한다.
classification 및 regression tasks의 경우, \(h\)는 fully-connection layer로 직접 전달되어 각각 class logits 또는 scores를 얻는다. training objectives는 classification tasks를 위한 CrossEntropy와 regression tasks를 위한 Mean Square Error loss이다.
span-based reading comprehension의 경우, \(h\)는 fully-connection layer로 전달되어 모든 tokens의 start logits \(s\)와 end logits \(e\)를 얻는다. position \(i\)에서 \(j\)까지의 candidate span score은 \(s_i + e_j\)라고 정의되며, \(j ≥ i\)가 예측으로 사용되는 maximum scoring span이다. (All the candidate scores are normalized by softmax)
prediction의 경우, pooled first token span score와 비교한다. \(s_{null} = s_0 + e_0\)에서 best non-null span \(s^{\hat i,j} = max_{j ≥ i}(s_i + e_j)\) 까지 비교한다. F1을 최대화하기 위해 dev set에서 threshold \(\tau\)을 선택하는 non-null answer를 \(s_{\hat i,j} > s_{null} + \tau\)일 때 예측한다.
experiments
setup
- PyTorch implementation of BERT
- pre-trained weights of BERT 사용
- 수정 없이 BERT와 동일한 fine-tuning 절차를 따름
-
extra SRL embedding volume이 original encoder 크기의 15% 미만이므로 모든 layer가 적당한 모델 사이즈가 증가하는 것으로 조정됨
- initial learning rate \(\{8e-6, 1e-5, 2e-5, 3e-5\}\)
- warm-up rate of 0.1
- L2 weight decay of 0.01
- batch size \(\{16, 24, 32\}\)
- maximum number of epochs \([2, 5]\) (depending on tasks)
- texts are tokenized using wordpieces with maximum length of 384 for SQuAD and 128 or 200 for other tasks
- dimension of SRL embedding = 10
- default maximum number of predicate-argument structures \(m\) = 3
task & dataset
9개 GLUE benchmark + SNLI + SQuAD 2.0
Reading Comprehension
MRC benchmark dataset
- SQuAD 2.0 : SQuAD 1.1의 100,000 questions + new 50,000 unanswerable questions
Natural Language Inference, NLI
reading a pair of sentences + judging the relationship between their meanings {entailment, neutral, contradiction}
- SNLI (Stanford Natural Language Inference)
- MNLI (Multi-Genre Natural Language Inference)
- QNLI (Question Natural Language Inference)
- RTE (Recognizing Textual Entailment)
Semantic Similarity
두 문장이 sematically equivalent 한지 예측
challenges : recongnizing rephrasing of concepts, understanding negation, handling syntactic ambiguity
- MRPC (Microsoft Paraphrase corpus)
- QQP (Quora Question Pairs)
- STS-B (Semantic Textual Similarity benchmark)
Classification
- CoLA (Corpus of Linguistic Acceptability) : 영어 문장이 linguistically acceptable 한지 판단
- SST-2 (Stanford Sentiment Treebank) : for sentiment classification, 영화 평론에서 추출한 문장이 positive 한지 negative 한지 판단
result
anlysis
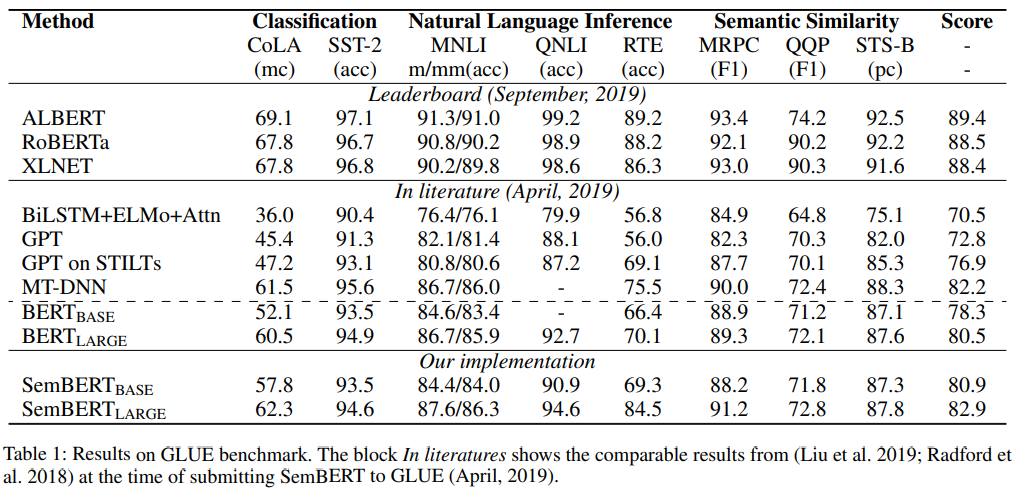
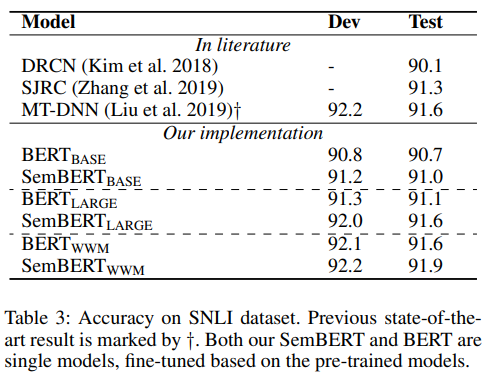
참고